

Data platform architectures have evolved drastically with time. From the early days, when databases with some bare minimum analytical capabilities were a single entity in the data architectural infrastructure, to a full-fledged central, master data repository powered by Data Lakes and Data Warehouses, not forgetting the modern Lakehouse approach to designing data architectures.
Table of Contents
However, the data, infrastructure, and team centralization have created another problem. As an organization scales, a single central data team or platform that handles all the data needs reaches a bottleneck, not to mention the struggle to keep up with the diverse and rapidly changing data demands across the organization.
In this article, we will talk about Data Mesh, a novel approach to designing a data architecture that will solve these issues and help us build a more reliable and scalable data infrastructure for our organization.
Let’s dive right in!!
What is a Data Mesh?

When we look at an organization’s structure, multiple domains and subdomains are linked to form a complete organization. The Data Mesh architecture does just that.
It segregates data, supporting infrastructures, and the team working on it by business function or specific domain within the organization.
Data Mesh makes distributed, domain-specific data consumption possible. It views data not as a service provided to data consumers but as a product of each domain. It is segregated, with each domain handling its data infrastructure and pipeline that runs on it. It contradicts a traditional monolithic data infrastructure that handles data storage, transformation, distribution, and output in one central data lake.
A Data Mesh introduces democracy to the organization’s data realm. It transfers control of the data and underlying infrastructures to domain experts, enabling them to craft meaningful data products under a decentralized governance framework.
Core Principles of a Data Mesh
When an organization moves its data platform design to a Data Mesh architecture, it takes more than just re-architecting the underlying infrastructure. It also requires a mindset shift for the whole arena of data management. And there comes yet another challenge to perfect the balance between agility and effective oversight.
However, the following four principles can be used as a beam of light on one’s journey toward Data Mesh without destroying it.
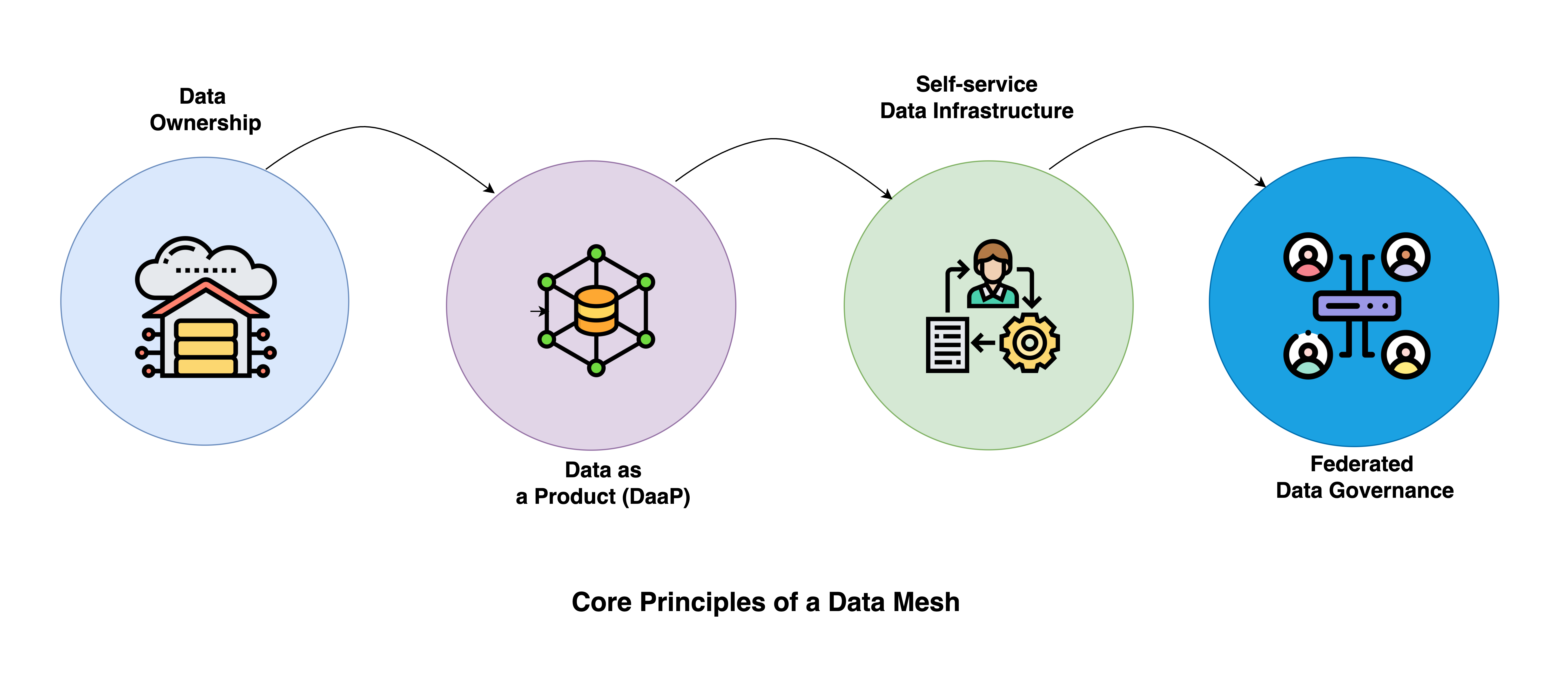
Domain-Oriented Decentralized Data Ownership and Architecture
This principle is based on distributing data ownership to every individual business domain rather than centralized under a single team. In this decentralized approach, each domain would be responsible for its data and better positioned to be agile and responsive to certain business needs. This structure can facilitate scaling in the ecosystem with increased data sources and use cases.
Some benefits of decentralized data ownership are as follows:
- It solves one of the prominent problems of any data platform architecture, i.e., ownership. Domain experts of each domain own their data set and register their ownership to a central data catalog for further due diligence.
- Distributed data architectures enable each domain to scale independently while each domain owns its pipeline and underlying infrastructure.
- A domain-specific team of experts, engineers, and analysts helps deliver solutions faster and more effectively.
Data as a Product
Data is viewed not as a service provided to data consumers but as a product of each domain. The data products developed in a data mesh are characterized by discoverability, understandability, and usability to the consumer. High-quality data should serve the user’s interests, improving his experience and increasing trust in the provided data.
Domain-specific teams define the data they own, produce, and share with other domain teams for cross-functional analysis. A data product can be as simple as a data table, a report, or a complex machine learning model that can be used further for descriptive and/or predictive analytics.
Self-Serve Data Infrastructure as a Platform:
This principle emphasizes how a self-service platform empowers domain teams to create, manage, and consume data products. By abstracting complexities in data management, one can realize value from data without technical challenges slowing them down.
Federated Computational Governance
Democracy without proper governance can result in anarchy. The same applies to data architecture. Thus, federated computational governance is the final and most important principle for Data Mesh architecture.
Federated governance would ensure compliance, quality, and standard processes to avoid chaos in a decentralized environment. The governance model will work automatically with policies, enabling the domain teams to focus on their data while complying with organizational standards and regulations.
Common Challenges and Solutions in Data Mesh Adoption
Adopting a Data Mesh architecture brings enormous benefits to the organization but also comes with some challenges. Let’s try to understand the challenges and possible solutions for successfully implementing a Data Mesh architecture.
- Organizational and Cultural Resistance
The decentralized data ownership model in the Data Mesh introduces cultural changes in an organization’s data unit. Data ownership lies with decentralized teams, and it is managed by a ‘data as a product‘ attitude. Not accepting that mind change greatly slows down the implementation.
Solution:- Strong leadership and executive level enablement towards the cultural changes.
- Comprehensive training and resources to educate team members regarding decentralized data ownership.
- Working on small pilot projects to craft success stories, validating new ideas.
- Well-defined Ownership of Data
Clear ownership of data sets is a complex object to assemble in a decentralized model, more so in a system that has been decentralized over time—more so when data spans across many domains.
Solution:- Clearly define the domains according to business capabilities. Attach ownership of data to domain teams in the best position to have proximity regarding business context regarding data.
- Clearly describe a data product owner—the individual responsible for data quality, documentation, and lifecycle management.
- Ensuring Data Quality and Consistency
Since the domains manage their data differently, attaining consistency across the organization becomes very difficult.
Solution:- Standardization and Best Practices: Institution of organizational-wide data quality standards and best practices by the organization. This will foster domains adhering to these standards, with flexibility to meet domain-specific needs.
- Automation—Testing and Monitoring: Data quality should be automatically monitored across the different domains. A data validation and testing framework that tracks issues early in the cycle would make this possible.
- Data Governance and Compliance
Decentralization might make it very hard to administer huge amounts of data in compliance with organizational and regulatory policies.
Solution:- Develop a federated governance model in which the standards are set globally, and domains still have the power to implement them in the best manner possible to suit their needs, thus pooling for consistent governance that would not stifle innovation.
- Data catalogs and lineage-tracking tools could assure the adequacy of visibility to the origin of data, its usage, and governance. It will foster compliance and ease auditing in data usage.
- Interoperability and Integration
As different domains drive their data, the interoperability of data products and the possibility of easy integration across the organization pose a challenge.
Solution- Promoting the use of standardized APIs and data interfaces, which makes it easy to share and integrate data across domains. Common data models shall only be defined in very few and exceptional cases to ensure compatibility.
- A culture shall be built across domains in which data product owners meet regularly, share insights and issues, and align regarding interoperability standards.
How to implement Data Mesh
Implementing a data mesh is not some twiddling of a few things; it is a significant shift in how the data team works, technology is used, and processes are managed. Defining a starting point can be overwhelming in a wide-reaching transformation like this.
Step 1: Decide what your Goal is.
- Access your current situation with data practice.
- Define concise objectives and engage with stakeholders to evaluate needs.
Step 2: Build Mesh Culture:
- Encourage Data as A Product (DaaS) Culture
Step 3: Decentralize across domains and define ownership:
- Identify business domains
- Assign data product owners for quality and management.
Step 4: Setting up the technology:
- Making the right choice of technology for decentralized data management.
- Build a self-serve data infrastructure.
Step 5: Enforce Governance:
- Draft data governance policies
- Create a federated data governance model.
Step 6: Ensure Interoperability:
- Standardizing data formats with data discovery and cataloging.
Step 7: Pilot and Iterate:
- Start with a small pilot project
- Experiment with new ideas.
Step 8: Monitor, Optimize and Scale
- Monitor KPIs to improve performance.
- Ensure flexibility for new technologies.
Data Mesh Use Cases:
Like many other data architectures, data mesh can facilitate multiple big data use cases. Let’s discuss some of them briefly.
- Data Analytics:
Interoperability in data mesh facilitates trusted, high-quality data across business domains. This helps teams collaborate and create customized BI dashboards, improving data insights and decision-making capabilities.
- Machine Learning:
Data standardization across domains makes it easier for data scientists to connect disparate data sources and accelerate the use of machine learning models and innovations.
Case Studies of Data Mesh Implementations
Let us look at some of the case studies of successful data mesh implementation, the problems it solved, and the benefits it brought to the organization:
- Intuit
Challenge: One of the major problems Intuit faced was regarding data discoverability and ownership. These were the two major concerns that hampered its data workers from accessing and using data efficiently.
Data Mesh Solution: The company rolled out a data mesh architecture by creating data products related to key business problems. The products are owned by a team that takes responsibility for governance, quality, and operational health. This gave data workers the autonomy needed to design, develop, and support their data systems with much less reliance on help from centralized teams.
Outcome: This made the data more accessible and less of a headache for data workers regarding data ownership and support. Intuit’s framework for data products mandated that all products be highly documented to drive trust and usability across organizations.
- JP Morgan and Chase
Challenge: Modernize the data platform while cutting costs and increasing the reusability of data across its huge business lines.
Data Mesh Solution: JP Morgan and Chase had a strategy in place—it was cloud-first, wherein every business line could generate and handle a data lake of its own. Now, in that type of setup, one would have created an intertwined set of data products whose policy is standardized. They put in a metadata catalog that keeps track of data lineage for accuracy and consistency in data.
Outcome: Thus, the decentralized approach brought greater flexibility in data management and better cross-team collaboration. Organized-wise, it ensured better quality and more trust in the data since any domain team owned its data products, driving efficacy in data operations.
Conclusion
Data Mesh represents a tectonic shift in how firms operate and scale their data infrastructure. A paradigm shift to the other pole emerges decentralization and domain orientation. Teams can autonomously own and manage their data without causing bottlenecks or losing the agility, quality, and collaboration of the data across the enterprise.
For a robust, resilient, and innovative data ecosystem, the excursion into decentralized architectures in evolution, of which Data Mesh is one feature. It would come to the fore when thinking about the continuous rate at which data has come to be thought of as a critical asset.
Hevo Data is a no-code data pipeline platform and which supports more than 150+ connectors, making it a standout choice for businesses looking for a reliable, cost-effective, and user-friendly platform. Sign up for Hevo’s 14-day free trial and experience seamless data integration.
Frequently Asked Questions on Data Mesh
1. Data Mesh vs. Data Lake?
Data Mesh is the decentralized ownership of data platforms across domains, and Data Lake is the centralization of raw data in one place.
2. What is the Difference Between Data Fiber and Data Mesh?
Data Fiber deals with data connectivity, and Data Mesh is concerned with decentralizing data ownership and management.
3. What is a Data Mesh in Layman’s Terms?
Data Meshes can be considered autonomous, small, dispersed data teams in which each team member is responsible for their data but follows mutual governance rules.
4. What is the Primary Objective of a Data Mesh?
Data management should be decentralized so that data can be accessed and managed easily throughout an organization.
5. Which is the Alternative to Data Mesh?
Centralized data architectures like Data Warehouses or Data Lakes are an alternative to Data Mesh.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link



