

Adopting data mesh changes how organizations approach and scale their data infrastructure. In contrast to traditional, centralized models of Data Lakes or Warehouses, the Data Mesh stance is that of decentralization and domain-centric management. It is based on the concept that every data team can manage and self-govern its data without bottlenecks but still with agility, quality, and collaboration across the enterprise.
Table of Contents
In this article, we will discuss Data Mesh in detail, exploring the architectural principles, key features, and considerations important for adopting this approach within your organization.
Let’s dive right in!
Overview of the Data Mesh Architecture
A data mesh is an architectural framework that solves sophisticated data security problems and scalability issues through distributed and decentralized ownership. This combines data sources across various business lines into analytics by unifying these disparate sources through centrally managed data sharing and governance guidelines. This allows business functions control over whom the data should be shared with and in what formats. By aligning data mesh implementation with sound data architecture principles, you can streamline data sharing, governance, and scalability while ensuring a robust and secure architecture. While it brings further complexities to the architecture, a data mesh makes the architecture more efficient through better data access, security, and scalability.
However, one might ask, why should I consider data mesh?
Organizations have an ever-growing stream of data that needs sorting, filtering, processing, and analysis to gain insights. Traditional organizational models of a central team of engineers and scientists that handle this data utilize a centralized platform to:
- Ingest data originating from different lines of business or domains.
- Transform the data into a standard format that can be used in some capacity; for example, standardizing the format of dates or rolling up daily reports.
- Prepare data for consumers through human reports or XML files for applications.
It can be very costly and inefficient to maintain the same level of agility with increasing volumes of data. The monolithic system is due to several scalability challenges, some of which are:
- Siloed Data Teams: The central team comprises data scientists and engineers with limited domain expertise handling diverse operational and analytical needs. They lack deep understanding or insight into specific business requirements.
- Slow Responsiveness: Any changes in the data pipelines become difficult to replicate throughout the system flow. This has to be managed by central teams with conflicting priorities and team members with less domain knowledge.
- Less Accurate: As the business units drift away from data consumers and the central team, there is a general apathy toward ensuring that the data supplied is meaningful, accurate, and useful.
Key Benefits of Data Mesh
With time, following the traditional data architecture approach could result in frustrated data customers, disconnected data producers, and an overwhelmed data management team. This is where Data Mesh architecture can play a vital role in addressing these challenges and delivering a more reliable and scalable data platform solution by introducing:
- Democratic Data Processing
A data mesh shifts control of data directly to domain experts who create meaningful data products in a decentralized governance framework. This means that data consumers ask for access to data products and contact data owners for approvals or changes. Faster access is given to everybody for data that matters to them, and faster access gives better business agility. - Flexibility
A centralized data infrastructure is more complex and requires collaboration, say, if someone wants to change or add new functionality. On the other hand, the data mesh rearranges the technical implementation of this central system into business domains. It eliminates central data pipelines, reducing operational bottlenecks and technical burdens on the system. - Cost Efficiency
Distributed data architecture moves away from batch processing and toward real-time data streaming. This allows for increased transparency of allocated resources and storage costs, hence better budgeting that reduces costs. - Improved Data Discovery
Data mesh prevents data silos from emerging around central engineering teams. It reduces the risk of data assets getting locked within different business domain systems; instead, it is governed and recorded by the central data management framework for data available in the organization. For instance, domain teams automatically record their data in a central registry. - Security and Compliance
Data mesh architectures ensure data security policies within and across domains. They provide a single point for monitoring and auditing the data-sharing process. For example, log and trace data requirements can be enforced against all your domains. Your auditors can view how often the data was used and in which form.
Looking for the best ETL tools to connect your data sources? Rest assured, Hevo’s no-code platform helps streamline your ETL process. Try Hevo and equip your team to:
- Integrate data from 150+ sources(60+ free sources).
- Utilize drag-and-drop and custom Python script features to transform your data.
- Risk management and security framework for cloud-based systems with SOC2 Compliance.
Try Hevo and discover why 2000+ customers, such as Postman and ThoughtSpot, have chosen Hevo over tools like AWS DMS to upgrade to a modern data stack.
Core Principles of a Data Mesh
The following four principles can be used as guidelines on your journey toward Data Mesh without destroying it.
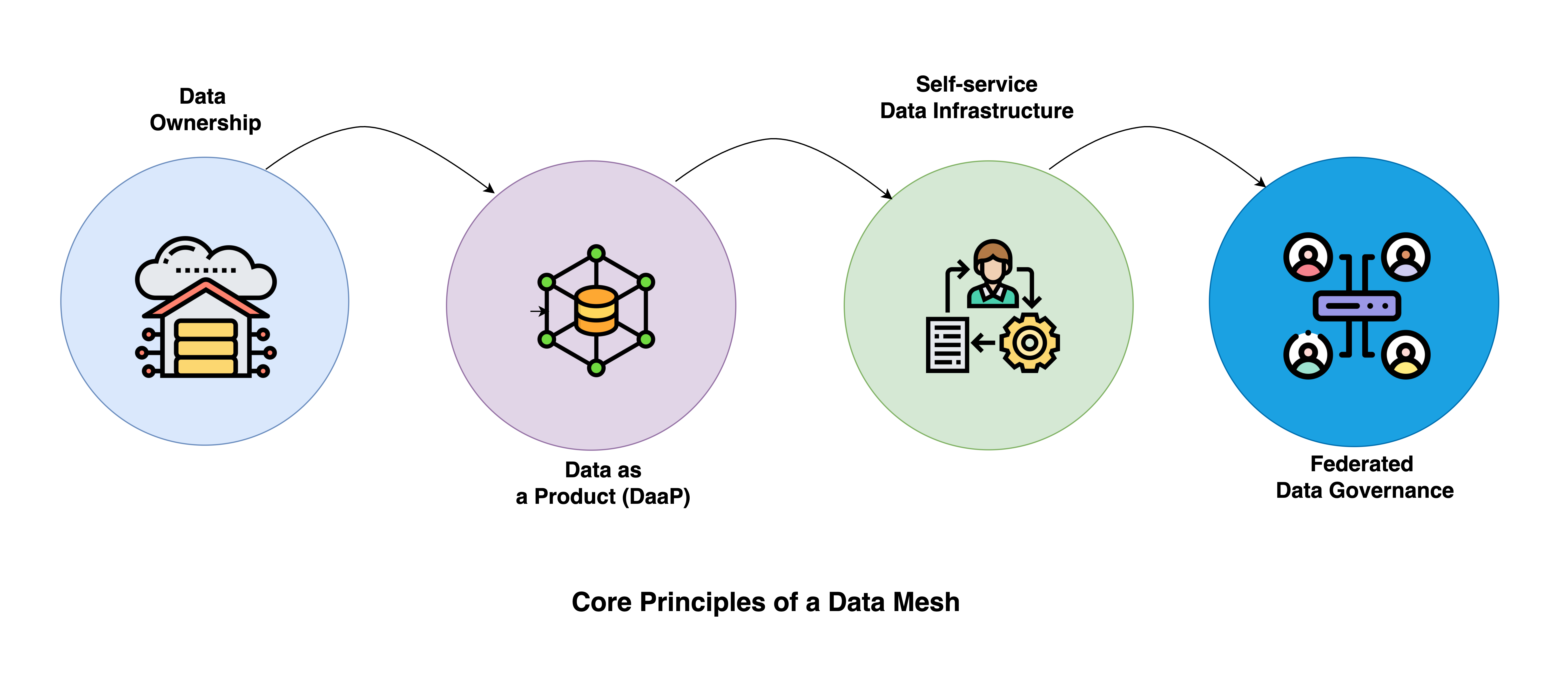
Distributed Domain-Driven Architecture
The data mesh approach arranges data management responsibilities by particular business functions or domains. This requires each domain team to collect, transform, and deliver data related to or generated by respective functions. The domains will not send the domain data to the central data platform; every team hosts and provides its datasets in an easy-to-use manner. For instance, a retailer may have a clothing domain with data on apparel and a website behavior domain with analytics regarding how his visitors engage.
Some benefits of decentralized data ownership are as follows:
- Defines the clear ownership of the data.
- Each data domain can scale independently and owns its pipeline and underlying infrastructure.
- Each domain has its team of data analysts, engineers, and domain experts, thereby decreasing the time needed to make any necessary changes to the domain data platform.
Data as a Product
When designing a data mesh architecture, every domain team should approach the dataset with a product attitude. They should treat their data assets as products and view other business and data teams as customers.
Below are some of the critical characteristics that any domain data product should possess to create the best user experience:
- Discovery: Every data product must be registered in a central data catalog to be easily discoverable.
- Addressability: Every domain data product must have a unique address for programmatic access and adhere to standard naming conventions specified by an organization.
- Trustworthy: Data products shall define service level objectives regarding the accuracy with which they can replay real-life events they record. For example, the domain of the order might publish data with the guarantee that the customer’s address and phone have been verified.
- Self-describing: Each data product shall be accompanied by a description of its syntax and semantics in a naming convention standard within the organization.
Self-Serve Data Infrastructure
Each domain in a truly distributed data architecture has to build its data pipeline to clean, filter, and load the data products. The data mesh adds a self-serve data platform to avoid duplication of efforts. Data engineers configure only the necessary technologies that allow the independence of all business units for processing and storing their data products. The self-serve infrastructure decouples responsibility; data engineering teams are responsible for the technology, and business teams are responsible for the data.
Federated Data Governance
In data mesh architectures, security is considered a group effort shared by everyone in the organization. The leadership establishes standards and policies globally across all domains, but the decentralized organizational structure grants domains significant autonomy in adhering to these standards and policies.
Functional Components of a Data Mesh Architecture:

Data Mesh’s architecture comprises the following core constituents: infrastructure, governance, data planes, and domain-oriented pipelines.
Now, let us discuss in depth each of the features above one by one.
- Infrastructure:
A typical data mesh architecture consists of the following infrastructural components:- Data Sources
Every independent domain within a Data Mesh can expose its data to a central metadata catalog. This helps discoverability and interoperability between domains. - Connectors
Connectors are libraries, drivers, or code on each domain’s data plane that help stream historical and incremental data changes. CDC (Change Data Capture) is one of the primary methods of data connectors. It monitors DB blogs to stream data to the processors. - Processors
Independent and reusable units of processing jobs that read events from the upstream transport apply various business logic and write data to the sink like Apache Iceberg tables, ElasticSearch, and Kafka stream. - Transport
When some business logic takes multiple intermediary stages to implement, the transport layer is used to hold intermediary results. They also help in tracking data lineage. - Schema
Data Mesh enforces a predefined template of schemas on all the pipelines and requires all the events passing through the pipeline to adhere to it.
- Data Sources
- Universal Governance
Federated data governance in a distributed architecture helps in frictionless data movement across independent data products.
This would require a governance committee underlying a federated model formed by owners of data products to ensure efficient and effective decision-making. Such global decisions on types should, therefore, consist of standard data asset definitions and capture rules for an organization, while offhand, some of the local decisions, for instance, data transformations, might vary domain-wise.
The governance committee needs to develop appropriate models of the data elements called polysemes, which have multiple meanings across multiple domains. Balancing centrally driven decision-making with domain autonomy is essential for an effective federated model.
- Data Planes
It is a logical interface and not a physical layer. Indeed, a single data plane could be supported by several physical interfaces. By all this, it puts particular care on the ability of a self-serve data platform. There are three types of data planes:- Data Infrastructure Plane: It represents the backbone of the data mesh, which is responsible for handling and managing everything that happens in the lifecycle of data infrastructure through distributed storage, access control, and data orchestration.
- Data Product Developer Experience Plane: Support in managing the end-to-end lifecycle of data products from build to manage and also provide a declarative interface for managing workflows.
- Data Mesh Supervision Plane: Discovery, management, and governance at the mesh level, therefore, decision-making on data product rules, norms, and policies, which help drive cross-domain analytics and data product discovery.
- Domain-Oriented Data Pipeline
A Data Mesh pipeline ingests data from multiple sources, applies transformations to the incoming events, and ultimately writes them to the destination data store. You can create a pipeline either through the UI or using our declarative API. When a pipeline is created or updated, the controller identifies the resources linked to the pipeline and determines the appropriate configuration for each resource.
Conclusion
To summarize, Data Mesh is the change of pace from traditional centralization models to a decentralized, domain-driven model that achieves high manageability and scalability. It ensures consistency and query ability across all domains, guarantees universal interoperability, and performs governance and high-quality observability.
This framework’s core components, which are the heart of domain-oriented data, data products, and data planes, drive organized data management, secure and discoverable data products, and efficient data infrastructure. Sign up for Hevo’s 14-day free trial and experience seamless data integration.
Frequently Asked Questions (FAQs)
1. What is data mesh architecture?
Data Mesh is a decentralized approach to data infrastructure that organizes data management around domain-oriented teams.
2. What are the 4 pillars of data mesh?
Data Mesh’s four pillars are
Domain-Oriented Data
Data Products
Data Planes
Federated Data Governance.
3. What is the lifecycle of data mesh?
The Data Mesh cycles through creating, managing, consuming, and evolving data products within its decentralized framework.
4. What is full mesh architecture?
Full Mesh Architecture is when each node directly links to every other node within a given structure.
5. What is mesh in architecture?
The mesh in architecture refers to a structure of interrelated elements that give stability and support.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link
