

With the constantly growing supply of tools for data processing, the issue of watching data lineage is critical. Thus, given that companies nowadays rely on data, it is more important than ever to determine how much data flows through different systems. This is where dbt (data build tool) comes into the picture. The dbt object is a SQL-oriented transformation tool that allows groups to quickly deploy analytics code conforming to software development methodologies such as modularity, portability, CI/CD, and documentation. The latest features empower anyone in the data team to freely deploy production-quality data pipelines.
Table of Contents
Moreover, dbt is currently a strategic solution for data handling and transformation in contemporary data structures. However, the most critical aspect is data lineage in dbt. Why does it matter? In this post, I answer the following questions: How does dbt solve the problem of data lineage, and what value does it bring?
What is dbt Data Lineage?
Data lineage documents how your data flows across your infrastructure and the changes occurring between the start and endpoint. In dbt, data lineage refers to the ability to track these transformations in the dbt model so that for any data point, one can quickly point you to the source of that data and each step between the pipeline.
Combining dbt with Hevo simplifies your data pipeline by seamlessly integrating data ingestion and transformation. Hevo’s no-code platform makes data integration effortless, while dbt handles robust SQL transformations directly in your warehouse.
Hevo Offers:
Built-In Data Quality: Provides features like schema mapping and error handling to maintain high data quality.
Automated Data Ingestion: Easily connects and loads data from 150+ sources with no coding required.
Real-Time Data Sync: Ensures your data is always up-to-date with real-time data sync.
How does dbt data Lineage Work?
1. Automated Lineage Generation
● Model Dependency Insights: dbt also builds a dependency graph on its own and shows how different models depend on each other. Not only does this map show relationships, but it is beneficial in organizing and debugging data pipelines.
● Dynamic Updates: Whenever dbt models are changed, the lineage data changes instantly, keeping the data dependencies current.
2. Visualization of Data Lineage:
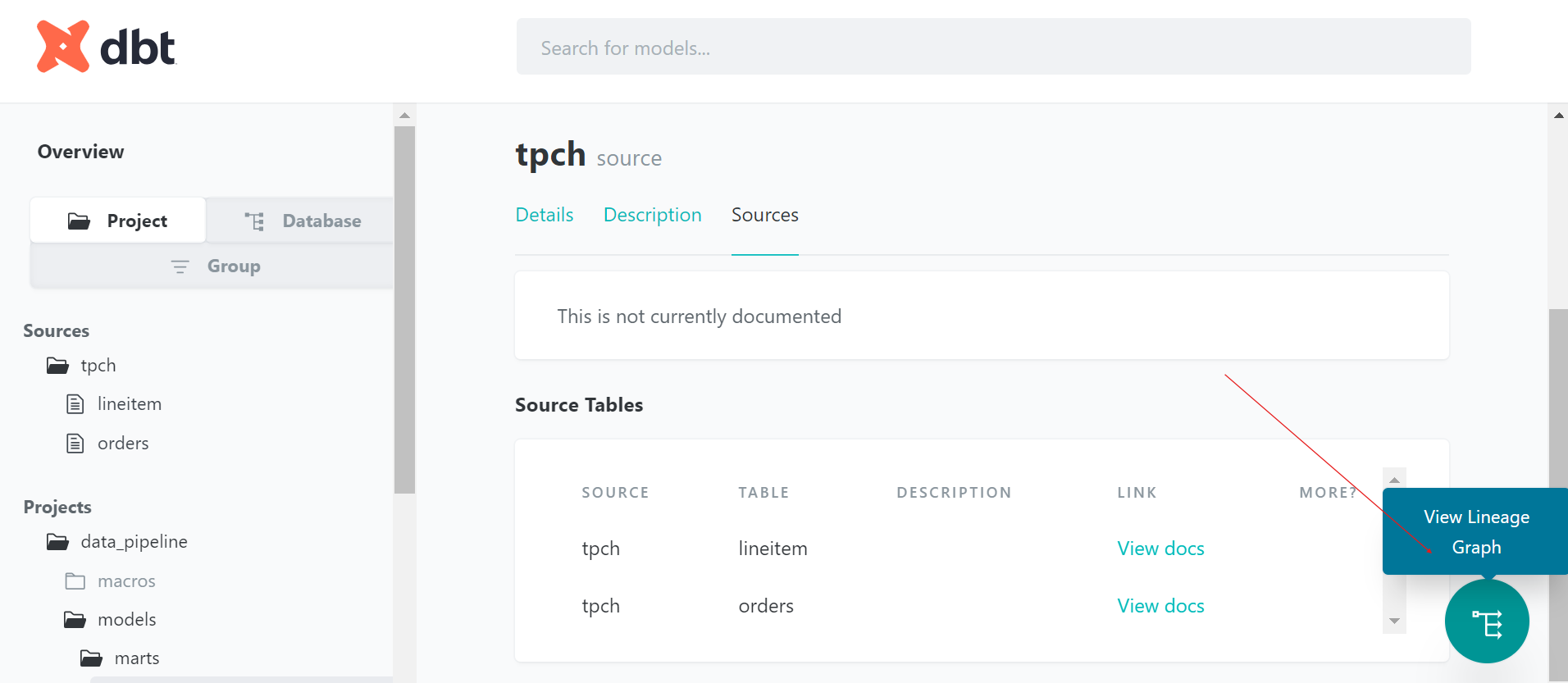
After we run the commands to generate the docs:
dbt docs generate
dbt docs serveWe will be on the same page as the above one. The page has a lot of information about your project data sources, models, targets, and tests.
Just click the symbol of View Lineage Graph, and then you will be directed to the data lineage page as follows:
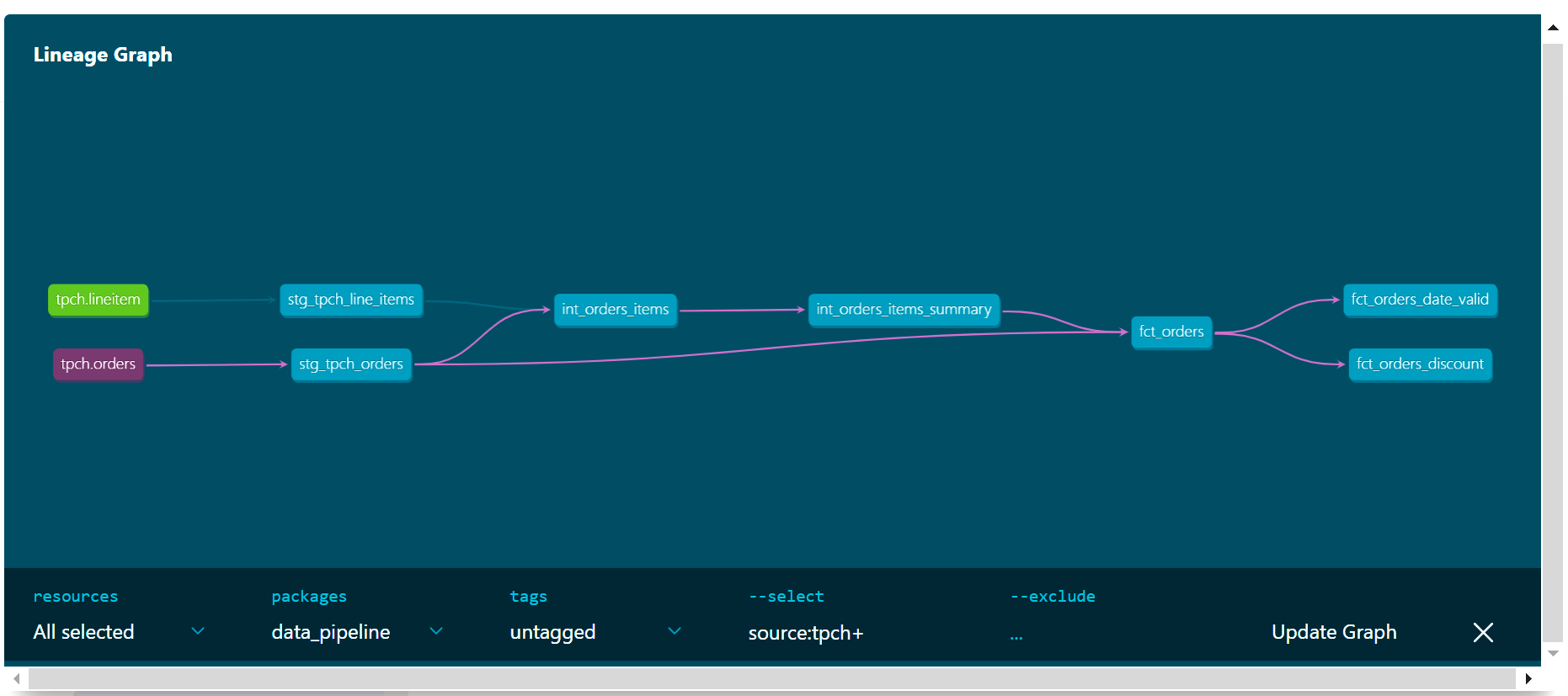
Here, you will find the Lineage Graph, which shows the data movement along the data pipeline. In my case, the source tables are:
“tpch_lineitem” and “tpch_orders”. The graph shows the staging tables, which are:
“stg_tpch_line_items” and “stg_tpch_orders”.
So you can see how the data flows and the dependencies across the tables.
Note: The sources from which we get the data and staging usually require some transformation before injecting the data into the pipeline for further transformation or analytics.
In general, dbt Data Lineage has many advantages as the following:
- User-Friendly Graphical Interface: It also uses a graphical representation of the data flow, which an analyst can quickly glance at to identify a problem or inefficiency.
- Interactive Exploration: This tool is a widget that interacts with the lineage graph; a user can explore the details of some models or a particular value to understand the data flow.
- The figure above shows the data lineage from the source tables: [tpch_lineitem, tpch. orders] to the target tables: [fct_orders_discount, fct_orders_date_valid] and how data transits.
- Technical Implementation: There are two commands which can be used to produce the data lineage, as it is shown below:
dbt docs generate
dbt docs serve3. Column-Level Lineage:
● Granular Visibility: Comparatively, with dbt, the data lineage is performed even at the column level to explain how specific data columns are processed in that model.
● Impact Assessment: Per column, lineage helps understand how changes to specific columns could affect the rest of the system and makes managing data more accurate.
4. Cross-System Lineage:
● Integration with External Tools: dbt supports lineage with other tools such as Atlan, Alation, and Collibra for lineage across systems. This integration also enables the integration of data intelligence maps across various platforms.
● Consistency Across Pipelines: By checking data lineage across several systems, dbt establishes trust and accuracy whenever it processes data in different stages.
5. Impact Analysis:
● Proactive Change Management: dbt has an exciting feature regarding the lineage where you can analyze possible consequences of changes you make before they go live. This will help prevent any future disturbance in data.
● Efficient Troubleshooting: Realizing the dependencies throughout the data pipeline leads to faster problem recognition and solving, which improves data quality.
For technical implementation, you can use the command:
dbt run –models [your-model-name]
6. APIs for Lineage Queries
● Custom Lineage Queries: dbt has APIs where a user can perform lineage queries that can be customized depending on the organization’s use.
● Seamless Integration: These APIs can also be used with BI tools to present the data lineage in a dashboard, thus improving your ability to handle the data.
For technical implementation, you can use the following script: For technical implementation, you can use the following script:
“import requests
response = requests. get('http://localhost:8080/api/v1/schemas')
lineage_info = response. json()
print(lineage_info)”What are the Benefits of dbt Data Lineage?
1. Better data quality
○ Early Error Detection: Following the flow of data, dbt pinpoints where data errors begin to correct the data before getting into the hands of consumers.
○ Transformation Validation: Genealogy facilitates confirmation of the data transformations at every step and guarantees that processes produce the right results.
2. Better organization of collaboration
○ Unified Team Understanding: Data lineage transforms better how teams work as it promotes an improved understanding of data usage and transformation by engineers and analysts involved.
○ Dynamic Documentation: The lineage maps are stored visually, making it more understandable for new members to view and thus know what the team has produced.
3. Compliance and Auditing
○ Regulatory Adherence: Some maneuvers in dbt’s lineage help achieve regulatory compliance as it records data flows, which are usually compulsory.
○ Comprehensive Audit Trails: Lineage tracking provides complete records to ensure the consistency and validity of information necessary to pass most kinds of audits, whether from academic institutions or governmental bodies.
4. Efficient Troubleshooting:
○ Root Cause Identification: When issues occur, lineage features embedded in dbt enable rapid identification of a problem’s source, drastically reducing the time needed to address it.
○ Change Dependency Management: Change can be instilled while controlling the risk that it will disrupt the data.
For technical implementation run the following command for testing: For technical implementation run the following command for testing:
dbt test --select model_name
Hevo Data Lineage with dbt
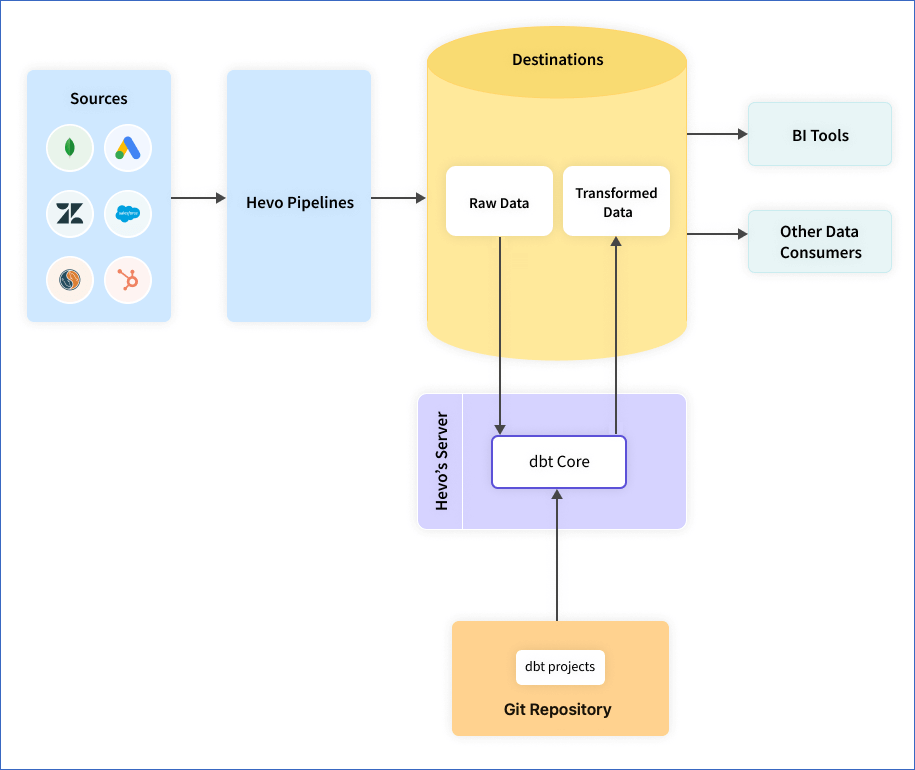
Hevo integrates seamlessly with dbt Core, allowing users to leverage the power of dbt’s transformation capabilities while benefiting from Hevo’s data lineage tracking. Data lineage in Hevo, when combined with dbt, offers a comprehensive view of how data is transformed and flows through your pipelines, making it easier to ensure data integrity and compliance.
Key Features of Hevo Data Lineage with dbt
- dbt Integration: Hevo enables you to configure dbt projects for popular data destinations such as BigQuery, Snowflake, Amazon Redshift, Databricks, and PostgreSQL. This integration lets you run dbt models directly from Hevo on your destination data.
- Version Control and Collaboration: By connecting Hevo with your existing dbt projects hosted on Git providers like GitHub, GitLab, or Bitbucket, you can maintain version control and collaborate effectively with your team. This ensures that all changes in your dbt models are tracked and documented.
- Scheduling and Automation: With Hevo, you can schedule dbt models to run at specific intervals or trigger them based on events in your destination tables. This automation ensures that your data transformations are up-to-date and the lineage remains accurate and current.
Steps to use Hevo with dbt
Step 1: Connect to your existing dbt projects created in any Git provider, such as Bitbucket, GitHub, or GitLab.
Note: You should have atleast read-only access to the Git repository.
Step 2: Run the dbt models on your Destination data.
Step 3: Configure a dbt project to run models on a specific branch in your Git repository, for example, to test your created models.
Step 4: Schedule your dbt project to:
- Run all of the models in your project together,
- Run each model individually
- Trigger your dbt project whenever Events are loaded to a specific Destination table.
Step 5: View the model execution history and the complete activity log for the dbt project. Integrate your dbt projects with Hevo Workflows.
Conclusion
Data lineage is a crucial aspect that every organization needs to learn to manage to achieve the goal of having good data and smooth-running systems. dbt provides the lineage and flexibility that helps ensure the data’s validity in the complex pipeline. ” When you scale your data infrastructure with solutions, such as Hevo, you can extend your lineage capabilities and guarantee traceability.
Connect with us today to transform your data integration experience.
FAQ
What is Data Lineage in dbt?
Data lineage in dbt traces the flow of data through the pipeline, showing how data is transformed from source to destination. It helps visualize dependencies and ensure data consistency.
What is dbt in Data?
dbt is a tool for transforming raw data in the warehouse using SQL, enabling data teams to build clean, analytics-ready datasets. It integrates with modern data warehouses for efficient data transformation.
Does dbt do Column-Level Lineage?
Yes, dbt supports column-level lineage, allowing you to trace the transformation of individual columns through the pipeline. This provides a granular view of data dependencies and transformations.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




