

The world of data management is evolving faster than we imagine. There are hundreds of products in the market for data management. Among those, the two data management concepts that are gaining traction within organizations are Data Mesh and Data Fabric. Both of these tools aim to solve the complex problem associated with data management.
Table of Contents
This blog will explore these concepts in depth, including their definitions, benefits, and key components, and compare Data Mesh vs Data Fabric.
What is Data Mesh?
Data Mesh is a decentralized data architecture that enables the individual business domain to manage the data. In traditional data architectures, a central data team manages the organization’s data. Data Mesh empowers individual domains to manage their data, thereby promoting faster and more efficient decision-making.
Principles of Data Mesh
Data Mesh is built on four foundational principles:
- Domain-Oriented Decentralization: Data Mesh has domain-oriented decentralization which means each domain manages its data. It is based on the principle that the data should reside/be handled by those who understand it better.
- Data as a Product: Data is treated as a product in Data Mesh, and each domain team is responsible for its quality, usability, and accessibility. When we define data as a product, the respective teams are to govern its end-to-end maintenance.
- Self-Service Data Infrastructure: Data Mesh has a self-serve platform where different teams can access and manage their data. The self-serve data platform provides domain teams the necessary tools and infrastructure to manage their data.
- Federated Computational Governance: The federation governs every domain in the organization. Each domain can operate independently, but global standards and policies are maintained across the organization.
Take a look at the above four principles in detail for a better understanding.
Benefits of Data Mesh
- Scalability: Centralizing data management is quite challenging in large organizations. Data Mesh has a scalable centralized data management system that distributes responsibilities across domains.
- Agility: By decentralizing data ownership, domains can adapt more quickly to changes in business requirements, thereby increasing the agility of the entire organization.
- Improved Data Quality: As the data is managed by an individual domain, who understands the domain better in terms of context and quality can ensure the quality of the data, leading to more accurate and reliable data.
- Reduced Bottlenecks: Centralized data teams often become bottlenecks in large organizations due to multiple teams accessing and updating the data. Data Mesh solves this problem by distributing tasks across multiple teams.
Tired of writing long lines of code for replicating your data? Unlock the power of your data by effortlessly replicating it using Hevo’s no-code platform. Use Hevo for:
- Integrate data from 150+ sources(60+ free sources).
- Simplify data mapping and transformations using features like drag-and-drop.
- Easily migrate different data types like CSV, JSON, etc., with the auto-mapping feature.
Don’t just take our word for it—try Hevo and discover how Hevo has helped industry leaders like Whatfix connect Redshift seamlessly and why they say,” We’re extremely happy to have Hevo on our side.”
Get Started with Hevo for FreeExamples of Data Mesh
Below are a few organizations that have successfully implemented Data Mesh to enhance their data management capabilities. By decentralizing data ownership, companies ensure that each domain can innovate and handle the data independently.
- Netflix: Netflix has adopted a Data Mesh architecture to manage its vast amounts of data across various business units, including content production, user engagement, and recommendation systems.
- Spotify: Spotify uses Data Mesh to manage its data across different domains, such as music recommendation, advertising, and user engagement. This approach allows each team to focus on delivering the best possible data product for their specific area.
- Zalando: The European e-commerce giant Zalando implemented Data Mesh to manage its complex data landscape across various departments, such as logistics, customer service, and marketing.
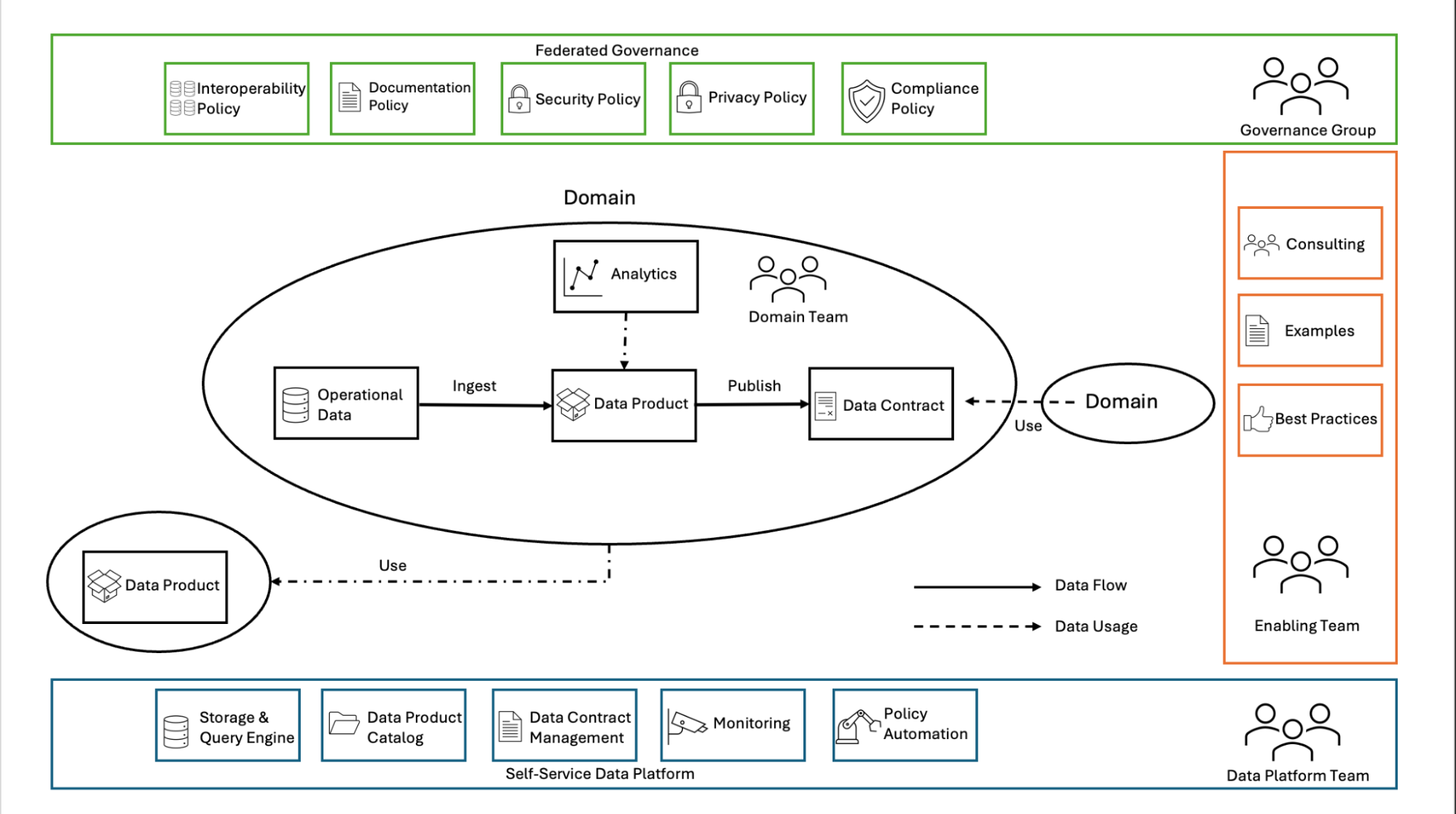
Data Mesh Architecture
Data Mesh Architecture is a decentralized approach that enables domains to manage and optimize their data independently. It is designed to address the challenges of scaling data operations in large and complex organizations, where data is often siloed across different departments or business units. The key architectural components of Data Mesh are –
- Domain Oriented Data Ownership
- Self Service Data Infrastructure platform
- Federated Computational Governance
- Distributed Data Architecture
- Data as a Product
- Data Product Interface and API
- Observability and Monitoring
- Evolutionary Architecture
What is a Data Fabric?
Data Fabric is a data management concept that provides a unified and intelligent data platform for data management. It seamlessly integrates with the Cloud, on-premise systems, edge computing devices, and various data sources. Data Fabric provides feature and technology services that enable data integration, data cataloging, data discovery, data orchestration, and more.
Data Fabric uses machine learning, data virtualization, and metadata management technologies to automate and streamline data processes. It is designed to provide a seamless data experience, enabling organizations to make data-driven decisions more efficiently.
Benefits of Data Fabric
- Unified Data Management: Data Fabric provides a unified approach to data access. Its unified platform makes data from various sources easier to manage and access. These sources may include structured and unstructured data, Relational Databases, NoSQL databases, Data Lakes, and Cloud storage.
- Enhanced Data Security: Data Fabric offers ultimate Data security. Although the data is managed centrally, Data Fabric ensures that the security features are consistently applied across all data assets.
- Improved Data Quality and Consistency: Data Fabric utilizes data from different sources, maintaining Data Quality and Consistency across the organization.
- Automation and Intelligence: Data Mesh uses Artificial Intelligence and Machine Learning to automate Data Management tasks such as data integration, quality control, and governance.
Examples of Data Fabric Solutions
Several organizations have implemented Data Fabric solutions to achieve a unified, consistent view of their data. Some of them are listed below –
- IBM: IBM’s Data Fabric solution integrates data across hybrid cloud environments, enabling organizations to manage, govern, and analyze data from a single platform.
- Informatica: Informatica offers an Intelligent Data Fabric that automates data discovery, integration, and governance across multi-cloud and on-premises environments.
- Talend: Talend’s Data Fabric platform provides tools for data integration, quality, and governance, allowing organizations to create a single source of truth across their data landscape.
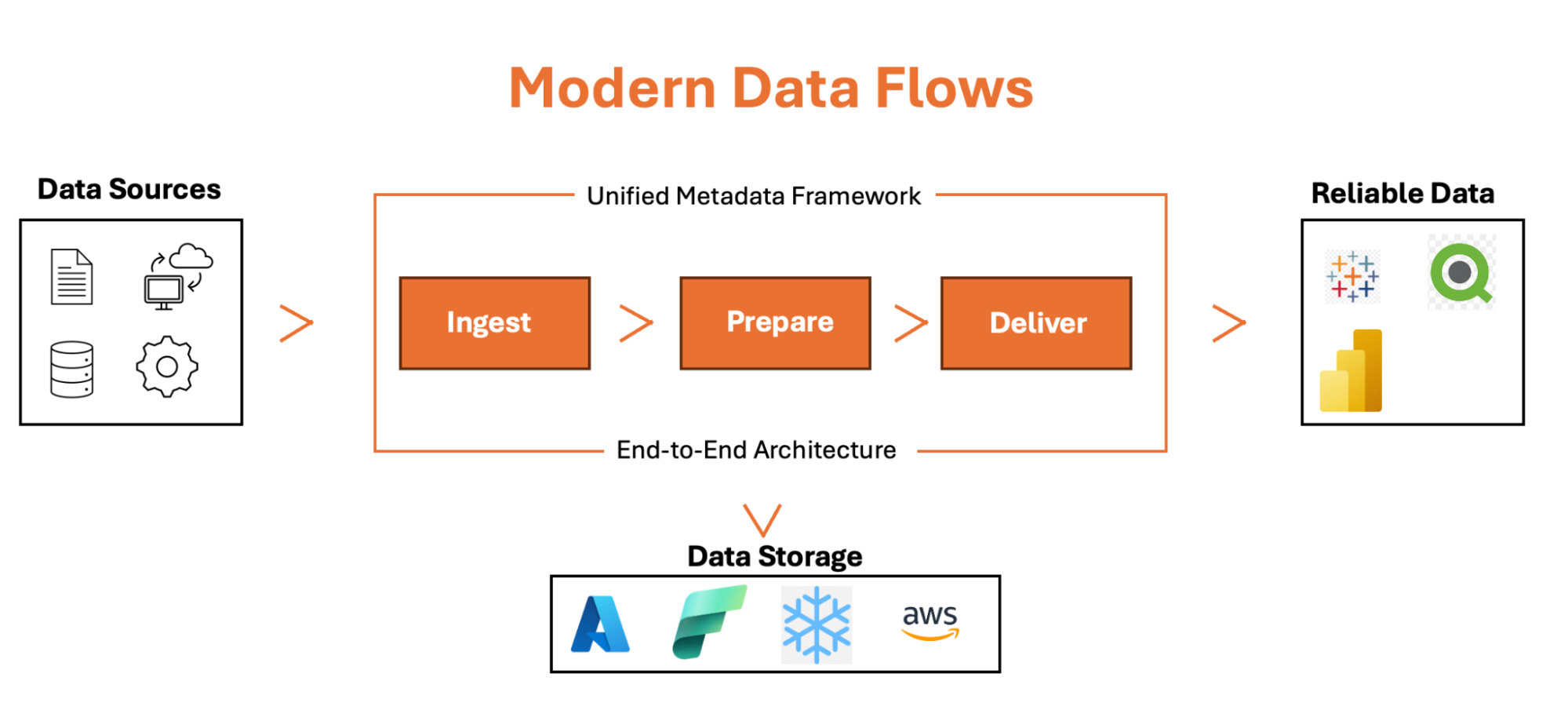
Architecture of Data Fabric
Data Fabric is a data management concept that provides a unified and intelligent data platform to manage the data. The key components of Data Fabric architecture are as follows –
- Data Integration: Data Fabric integrates data from multiple sources, including RDBMS, structured and unstructured data, cloud, on-premises, and edge computing environments, to create a unified view for accessing the data.
- Data Virtualization: Data Fabric uses data virtualization to provide real-time access to data without requiring physical data movement, reducing latency and complexity.
- Metadata Management: Data Fabric effectively manages the metadata of the data. The Data Fabric platform understands the relationship between different data assets using ML and AI and, hence, provides a unified view to the end users.
- AI and Machine Learning: Data Fabric uses Artificial Intelligence and Machine Learning to automate data management tasks such as data ingestion, quality control, security, data governance, and integration. All these features make Data Fabric intelligent and adaptive.
- Security and Compliance: Data Fabric ensures that security and compliance policies are consistently applied across all data assets, regardless of where they reside.
Data Mesh vs Data Fabric: Key Differences
| Aspect | Data Mesh | Data Fabric |
| Architecture | It is a Decentralized, domain-oriented architecture | It is a Centralized, unified data platform |
| Data Ownership | Each domain owns and manages its data. | Centralized ownership with a unified management |
| Scalability | It scales through decentralization of the data across nodes. | It scales by integrating and unifying data sources and providing a unified view. |
| Governance | Federated governance across domains. | Centralized governance across the organization. |
| Data Management Approach | Data is mangned as domain-specific, and data is treated as a product | Data is managed as Unified data management across environments |
| Technology Focus | Domain-oriented infrastructure and tools | Data integration, virtualization, AI, and ML |
| Use Case Fit | Best for organizations with diverse, domain-specific needs | Ideal for organizations needing a centralized, consistent data view |
| Implementation Complexity | Requires cultural shift and domain expertise | Requires sophisticated integration and management tools |
You can also take a look at our detailed comparison of data fabric vs data lake to understand their key differences and how they support modern data management.
When to Choose Data Mesh
Data mesh is particularly well suited for organizations with diverse data needs that contain huge amounts of data. It’s ideal when –
- Decentralized Architecture: When an organization has multiple domains/business units and deals with huge data, a decentralized approach is required to efficiently manage the data by their respective domains.
- Domain Expertise: If the organization has domain expertise that can effectively manage the data, then it can benefit from Data Mesh autonomy.
- Need for Agility: The organization needs to quickly adapt to changing business needs, and centralized data management would create bottlenecks.
Challenges and Considerations for Implementing Data Mesh
Implementing Data Mesh comes with its own set of challenges:
- Cultural Shifts: Data Mesh is fairly a new concept, and transitioning from traditional architecture to a Data Mesh architecture requires a cultural shift, where domains take on more responsibility for data management.
- Infrastructure Demands: Data Mesh requires heavy infrastructure to decentralize the data. Each domain needs access to the necessary tools and infrastructure, which can require significant investment.
- Governance Complexity: Data governance is of utmost priority for any organization. Ensuring consistent governance across decentralized domains can be challenging, and requires a detailed approach towards it.
Best Practices for Successful Data Mesh Adoption
- Invest in Training the domain teams to have the necessary skills and knowledge to manage their data effectively.
- Build a robust self-service infrastructure for domain teams to use so that they can manage their data independently.
- Establishment of clear governance frameworks to ensure consistency and compliance across all domains.
When to Choose Data Fabric
Data Fabric is ideal for organizations that require a centralized, unified approach to data management. It’s best suited for:
- Centralized Management: Organizations that need to maintain a consistent view of data across multiple sources and environments.
- Data Consistency: When it’s crucial to ensure that data is consistent, accurate, and up-to-date across the entire organization.
- Complex Data Environments: The unified approach of Data Fabric can benefit organizations dealing with complex data environments, including multi-cloud, on-premises, and edge computing.
Challenges and Considerations for Implementing Data Fabric
Implementing Data Fabric also presents challenges:
- Complexity: Building and maintaining a data fabric architecture can be complex, requiring sophisticated tools and expertise.
- Cost: Data Fabric relies on AL and ML. Integrating these technologies is expensive to implement and maintain.
- Data Governance: Ensuring consistent governance across a centralized platform can be challenging, especially in complex environments.
Best Practices for Successful Data Fabric Adoption
- Invest in the Right Tools: Choose robust data integration, virtualization, and AI tools that support your organization’s data fabric strategy.
- Comprehensive Metadata Management: Proper metadata management is essential for understanding and managing the relationships between data assets.
- Focus on Security and Compliance: Ensure your data fabric platform supports consistent security and compliance policies across all data assets.
- Plan for Scalability: Design your Data Fabric architecture with scalability in mind to accommodate future growth.
Integrating Data Mesh and Data Fabric: A Hybrid Approach
Can Data Mesh and Data Fabric Coexist?
Yes, Data Mesh and Data Fabric can coexist, and in some cases, combining both approaches can provide significant advantages. A hybrid approach leverages the strengths of both architectures, offering flexibility and scalability.
Use Cases Where a Hybrid Approach May Be Advantageous
- Large Enterprises with Diverse Needs: In organizations where different domains have unique data requirements, Data Mesh can provide the necessary decentralization of the data, while Data Fabric ensures that data remains consistent and accessible across the organization.
- Global Organizations: In global companies with operations in multiple regions, Data Mesh can empower regional teams, while Data Fabric ensures that data is harmonized and accessible globally.
Strategies for Integration
Effectively integrating Data Mesh and Data Fabric requires careful planning and the right tools:
- Align on Governance: Establish a governance framework allowing domain autonomy while ensuring that global standards are met.
- Use of Interoperable Tools: Choose tools and frameworks supporting decentralized and centralized data management.
- Foster Collaboration: Encourage collaboration between domain and central data management teams to ensure seamless integration.
By adopting a hybrid approach, organizations can achieve the best of both worlds, leveraging the scalability and flexibility of Data Mesh with the consistency and intelligence of Data Fabric. This integrated strategy allows for a more dynamic and responsive data architecture that can adapt to the ever-changing needs of the modern enterprise.
Also, take a look at the differences between Data Mesh vs Data Fabric vs Data Lake to get an overview of all the three important concepts.
Conclusion
Data Mesh and Data Fabric are two distinct approaches to modern data management, each with its unique strengths and challenges.
Data Mesh is a decentralized, domain-oriented architecture that empowers individual teams within an organization to manage their data as a product. This approach is particularly well-suited for large, complex organizations with diverse and domain-specific data needs.
On the other hand, Data Fabric offers a centralized, unified data management platform that integrates and harmonizes data across various environments, including on-premises, cloud, and edge computing platforms. Data Fabric is particularly advantageous in environments where data consistency, governance, and real-time accessibility are paramount.
Sign up for Hevo’s 14-day free trial and experience seamless data management.
Frequently Asked Questions
1. What Is the Difference Between DataOps and Data Fabric?
Data Fabric: An architectural approach that provides a unified data management framework, enabling seamless data access and integration across a variety of environments.
DataOps: A practice that focuses on improving the efficiency and quality of data analytics through agile methodologies, collaboration, and automation.
2. Why Is Data Mesh Considered Obsolete?
Data mesh can be complex to implement, making it challenging at scale and leading some to prefer simpler solutions.
3. Is data fabric the same as data mesh?
No, Data Fabric and Data Mesh are not the same:
Data Mesh: Focuses on decentralized data ownership and domain-specific management, promoting a more federated approach to data infrastructure.
Data Fabric: Provides a unified architecture for managing and integrating data across various environments and platforms.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




