

With numerous file formats and data generated daily, your organization needs a data infrastructure tailored to its specific needs. A monolithic approach, like a data lake, stores all the data in one place with right permissions set for accessibility.
Table of Contents
However, with recent advancements, a new decentralized architecture—data mesh—has emerged, promising comparable storage capabilities with improved flexibility.
In this article, we’ll explore data mesh vs. data lake, their unique benefits and challenges, and help you choose which data architecture is right for you.
Table of Comparison: Data Lake vs Data Mesh
| Criteria | Data Mesh | Data Lake |
| Architectural Approach | Decentralized architecture | Centralized architecture |
| Data Ownership | Different domain teams own and manage the data they use | Entire data is owned and managed by a single central data team |
| Scalability | By adding more domain teams or scaling individual domains | By adding more nodes and computing resources |
| Data Integration | Domain-specific data products | Integrates centrally with many big data tools and platforms |
| Flexibility | More flexible with domain specific data products and APIs for accessibility | Moderate flexibility with centralized access |
| Governance and Compliance | Adheres to both global compliance rules and domain-specific policies | Follows global standards set centrally |
| Implementation Complexity | Initial setup and implementation is complex | Comparatively simple implementation |
| Cost Efficiency | Cost is optimized based on domain specifics | Cost-effective for storing large amounts of data |
| Top companies offering solutions | Thoughtworks | Cloud-services like AWS, GCP, Azure, and Snowflake |
Looking for the top ETL tools to streamline your data integration? Hevo’s no-code platform has you covered. With Hevo, your team can:
- Integrate data from 150+ sources (60+ free sources)
- Leverage drag-and-drop features or custom Python scripts for data transformation
- Benefit from a secure, cloud-based system with SOC 2 compliance
Join 2000+ customers who trust Hevo over Fivetran and Stitch to power their modern data stack. Try Hevo today and elevate your ETL process!
Get Started with Hevo for FreeWhat is a Data Mesh?
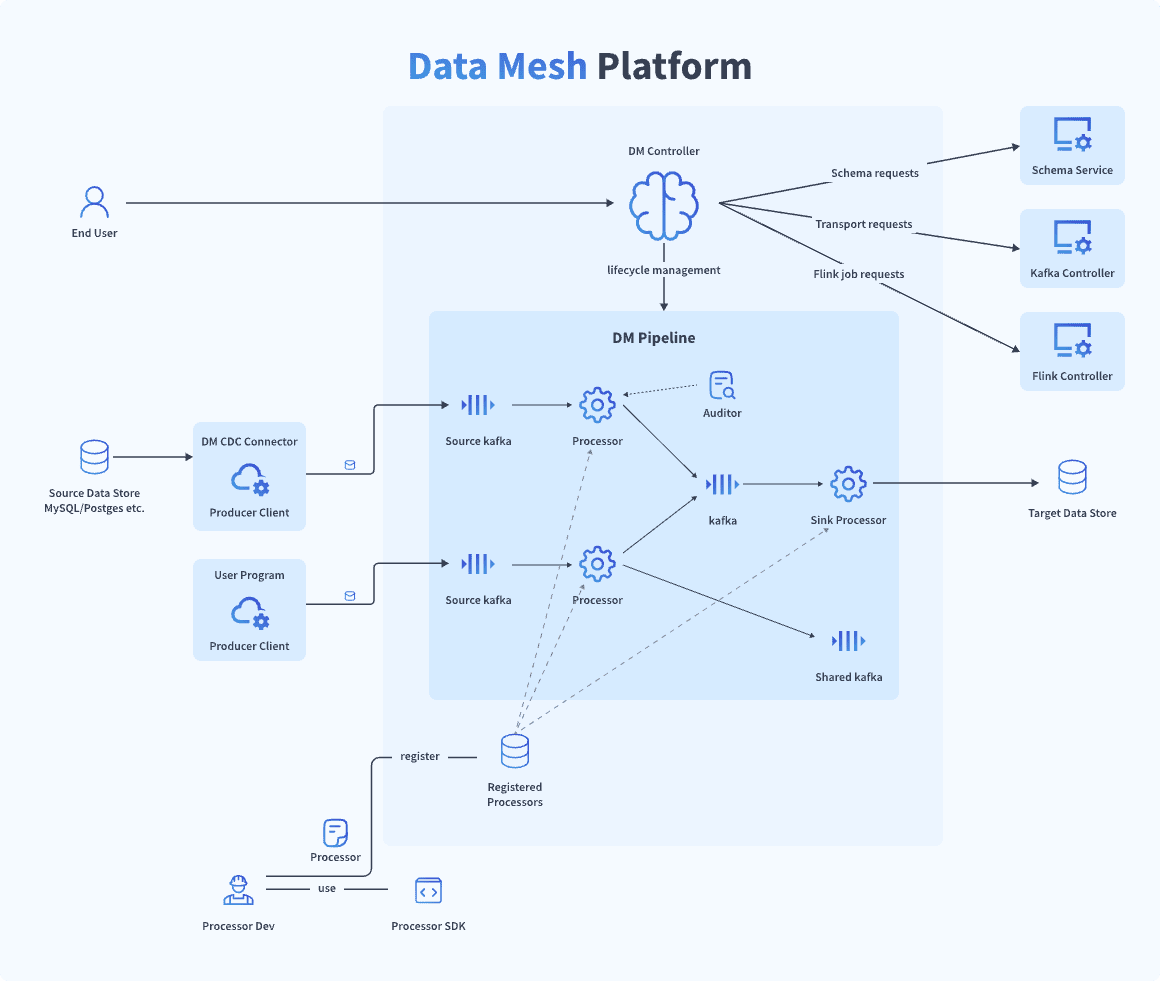
Data mesh architecture decentralizes data, allowing different teams of an organization to own and manage the data they use.
The data ownership is transformed to its specific business domains such as finance, marketing, sales, HR, and security that serve and manage data as a product.
This is a significant mindset shift from the idea of storing entire data at one place, to having different data managed by domain experts who treat it as a product. For example, the finance domain holds the finance data of an organization and controls its accuracy, availability, and access rights.
Key Principles of Data Mesh
Data mesh is based on the following four principles. When implemented rightly, they ensure that you have an efficient and accurate data mesh built into your infrastructure.
1. Domain ownership
Individual teams take over the ownership and responsibility for their domain-specific data. For example, the sales team manages sales data, the finance team handles accounting data, and the marketing team controls customer data.
By responsibility, we mean that the domain owner takes care of everything: managing, storing, processing, and securing the data they own.
2. Data as a product
Data is seen as a product, meaning each dataset is managed end-to-end to maintain accuracy, usability, and reliability. This approach allows anyone to easily find a data product through a centralized catalog. Each domain will also provide API access for their data products, enabling programmatic access to others.
3. Self-service data design
Not all domain teams will have the technical skills required to create, deploy, and maintain data pipelines end-to-end. That’s where this third principle—self-service data platform comes in.
Here, a dedicated, domain-agnostic team builds a self-service data platform that other domain teams can use to create their data products without much technical expertise.
The team can leverage cloud services like AWS, Azure, and GCP to develop this self-service data platform that anyone can adopt.
4. Federated governance
Different data products owned by different domain teams must adhere to some common global compliance standards. That’s the purpose of this fourth data mesh principle, federated governance.
A central data governance team establishes standards for data quality, retention, and compliance. Each data product must adhere to these global standards while also following the security rules set by its domain owner, ensuring data safety and privacy across the organization.
Benefits of Data Mesh
- As individual teams manage their own data, they become more accountable for ensuring its security.
- Enhanced data discoverability can be achieved through a centralized catalog that stores metadata information. The catalog provides a user-friendly interface for users to search and explore different data products across the organization.
- Domain teams have more flexibility in choosing the tools and frameworks they want to use for their data.
- You can have tailored data governance principles for each data product.
- It offers fast and flexible adjustments based on demand, without requiring central team’s approvals for changes.
- Domain teams share their data products through user-friendly interfaces, amplifying communication across the organization.
Challenges with Data mesh
- Not all your business teams have the technical skills required to adapt a self-service data platform.
- Initial data mesh setup in your organization can be complex. You’ll need to decide which domains own specific data, develop a user-friendly self-service data platform, establish access rights, and more.
- There is a risk of data silos if domain teams fail to access or share data with other teams in the organization.
- Data mesh architecture is a significant cultural and mindset shift for teams.
What is a Data Lake?

A data lake is a storage repository that holds large amounts of structured and unstructured data in its native format. The architecture stores it with tags and unique identifiers so that only required data is fetched at the transformation stage to avoid unnecessary data being loaded.
This is a paradigm shift from ETL(Extract, Transform, and Load) to ELT(Extract, Load, and Transform). In ELT, data is first stored and then is presented on-demand based on the search criteria.
Key Components of a Data Lake Architecture
A matured data lake architecture will have the following layers, from sourcing data to processing it.
1. Data ingestion layer
In this stage, data from various sources—such as NoSQL/SQL databases, streaming platforms, Google Forms, or IoT devices—is ingested. The data remains in its raw, unprocessed format at this point. The data is ingested either in real-time or in batches, depending on the requirement.
2. Distillation layer
At this stage, the data from the ingestion layer is transformed into a structured format and stored in files or tables for analysis. Here, the data becomes uniform, with a consistent encoding, data format, and data type, making it ready for further processing.
3. Processing layer
This is where user queries are executed on the data stored in the data lake. Analytical tools and business applications access data from this layer for AI/ML needs. It supports both batch and real-time processing, enabling efficient data consumption for various use cases.
4. Insights layer
This layer acts as the query interface for the data lake. It enables the use of traditional SQL or NoSQL queries to extract and analyze the data, helping you draw valuable insights for informed business decision-making.
5. Unified layer
The layer is responsible for monitoring and managing the workflows involved in the data lake. It ensures the seamless flow of data between stages in the correct order, allowing seamless orchestration between pipelines.
For workflow management, the layer tracks the status of data flow and maintains necessary logs to detect or solve failures.
6. Benefits of Data Lake
A data lake supports various formats of both structured and unstructured data, no more data silos issues, and a lot more benefits. Let’s explore some top ones here.
- With a data lake, you don’t always need to know the structure of the data before storing it. This flexibility makes it easy to integrate data from real-time sources like streaming platforms and IoT devices.
- Data lake is a scalable solution that can store vast amounts of data at a relatively low cost.
- Popular cloud storage services like S3, Azure Blob Storage, and HDFS support data lake architecture.
- You can scale computing and storage resources up or down as needed, ensuring you only pay for what you use.
Challenges Faced with Data Lake
- With data stored in a central location, the risk of unauthorized access can increase.
- If not managed properly, querying from a massive unstructured data from a single location can be slow and resource-intensive.
- Since entire data is stored in a single place, a small failure in the data lake can lead to entire data loss or downtime.
- Maintaining data quality, accuracy, and security is challenging due to the large volume of data and the variety of data formats.
Check out these detailed data lake challenges and solutions to overcome them.
Detailed Comparison: Data Mesh vs Data Lake
Data mesh leans towards a domain-oriented, self-service data management approach, transferring ownership to specific departments. In contrast, a data lake follows a monolithic approach, with a central storage system for both structured and unstructured data.
Here’s a detailed comparison of data mesh vs. data lake across various factors:
Architecture
A data lake follows a hybrid architecture with different layers handling tasks like storage, integration, and metadata management. While data mesh follows a distributed architecture with data ownership assigned to respective domains.
In a data lake, a common data team owns and manages all the data pipelines. Meanwhile, in a data mesh architecture, respective domain owners manage their own data pipelines and control their dedicated storage and processing resources.
A data lake can serve as a storage system for individual domains data in a data mesh, but it’s not a complete data architecture for the entire organization.
Data Storage
In a data mesh, data stored within each domain can leverage different storage structures. For example, the sales domain can have their data in a data warehouse while the engineering department of the company can save their data in a data lake architecture.
However, in a data lake, the entire data is stored in a single location, typically a cloud-based storage platform, in its raw format.
Data governance
The data lake architecture implements global and consistent rules across all the data stored, making it easier to manage.
But with data mesh’s federated computational governance principle, organizations strike a right balance between global data security standards and tailored data quality needs. In this approach, domain teams define their own data access controls and compliance rules that are tailored to the domain-specific needs, while also adhering to global security standards.
This allows data mesh to achieve both domain-level data quality and organization-wide security compliance.
Scalability
With data owned by different domains, scalability becomes more flexible in a data mesh. Each team can scale their data products according to their specific needs, choosing the storage infrastructure that best suits them. For instance, the engineering domain might opt for a cloud solution for extended scalability, while the security domain could choose on-premise storage for enhanced security and adequate scalability.
On the other hand, data lakes achieve scalability through distributed storage systems and parallel processing. Although data is accessed from a single central location, this repository utilizes multiple storage locations to distribute the data.
The central repository knows where to find the required data when queried. This setup allows optimal resource utilization by allocating them to distributed nodes based on demand, promoting parallel processing.
Analytics Tools
In a data mesh, domain teams have the flexibility to choose which technology to leverage for their data. This enhances the accessibility to tools and frameworks that can be tailored to different domain needs in a company.
Data lakes support a wide range of processing tools and frameworks, including Apache Spark, Apache Hive, Apache Hadoop, and more. Teams can leverage these technologies for data transformation, data ingestion, and data analytics tasks. Data lakes can also accommodate both batch and stream processing analytics needs.
Cost
In data mesh, cost varies according to the resources and technologies that each team uses for their data products. Teams handling less critical data can choose cost-effective solutions, while teams managing sensitive or critical data can invest in advanced solutions.
Data lakes are cost-efficient depending on the amount of data you store. Leveraging cloud platforms like AWS, Azure, and GCP benefits you through the pay-as-you-go pricing models, allowing you to pay only for resources you use.
Which Architecture Should You Choose?
Both data mesh and data lake have their own strengths and weaknesses. So choosing between them depends on the specific needs of the organization. You can also leverage both in case your data is that demanding. For example, you can structure data as a data mesh and each domain team can implement data lake architecture to store and process their data.
Data mesh is best when:
- You have complex cross-functional teams with multiple domains
- Your data needs to be tailored to different domain use cases
- You require a horizontally scalable architecture.
- You have many different sources and data types.
- You need more flexibility in choosing the tools and technologies tailored to different domains data.
Data lake is ideal when:
- You are in the initial stages of business that needs a platform for storing and analyzing data.
- You need a single source of truth for vast amounts of data.
- You have a central and common team of data scientists and analysts.
- Cost effectiveness is your top priority.
- Your team has limitations in technical expertise.
- You need straightforward and easily manageable governance rules.
Conclusion
The main difference between a data mesh and data lake is that a data mesh is designed for an enterprise with complex organizational structure and cross functional teams. Meanwhile, a data lake provides access to both unstructured and structured data from a central location.
Whether you choose a data lake or a data mesh, a data pipeline platform like Hevo ensures a seamless flow of data between pipelines, simplifies ELT processes, and flexible data transformation. For example, if you choose a data lake, Hevo simplifies ingesting data from various sources into your central repository. In case you opt for data mesh, Hevo provides an intuitive interface for domain teams to create and manage their own data pipelines.
Schedule a personalized demo with Hevo for a seamless data integration experience.
Frequently Asked Questions
1. How is data mesh different from data lake?
Data mesh is a decentralized architecture where individual domain teams own and manage the data that belongs to their business unit. On the other hand, data lake stores large amounts of data in a central repository.
2. What is the difference between data mesh and lakehouse?
Data lake stores vast amounts of data in a central repository while lakehouse is a unified platform that combines the benefits of data lakes and warehouses.
3. What is the difference between databrick and data lake?
A data lake is a central storage solution that can store and process large amounts of data in its native format. On the other hand, Databrick is a unified analytics platform that allows all users to easily access and analyze big data.
4. What is the difference between data warehouse and data mesh?
Data warehouse is a central repository that can store and process only structured data while data mesh is a decentralized architecture where each domain team is responsible for the storage and structure of the data they own.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link


