

Reliable and current data is extremely valuable for a variety of systems and applications. Because of this, data synchronization is an essential component of contemporary data management that has the power to make or break the precision and effectiveness of your company’s operations.
Table of Contents
This blog will discuss data synchronization, its methods, types, process, tools, examples, benefits, and challenges.
What Is Data Synchronization?
The continuous process of making sure that data is current and consistent across several devices or systems is known as data synchronization. For data to stay current over its lifetime, synchronization is essential. Errors are prevented, privacy violations are avoided, and the most recent data is always accessible, thanks to this instant update.
What Are the Different Data Synchronization Methods?
To preserve data correctness and network efficiency across settings, data synchronization technologies depend on a number of continuous procedures and systems. Important procedures consist of:
1. File Synchronization
When modifications are made to the authoritative file, file synchronization ensures that all instances of the file are updated as well. Synchronization software examines the files and makes the required updates automatically, saving the user from having to manually identify altered files and copy each one individually.
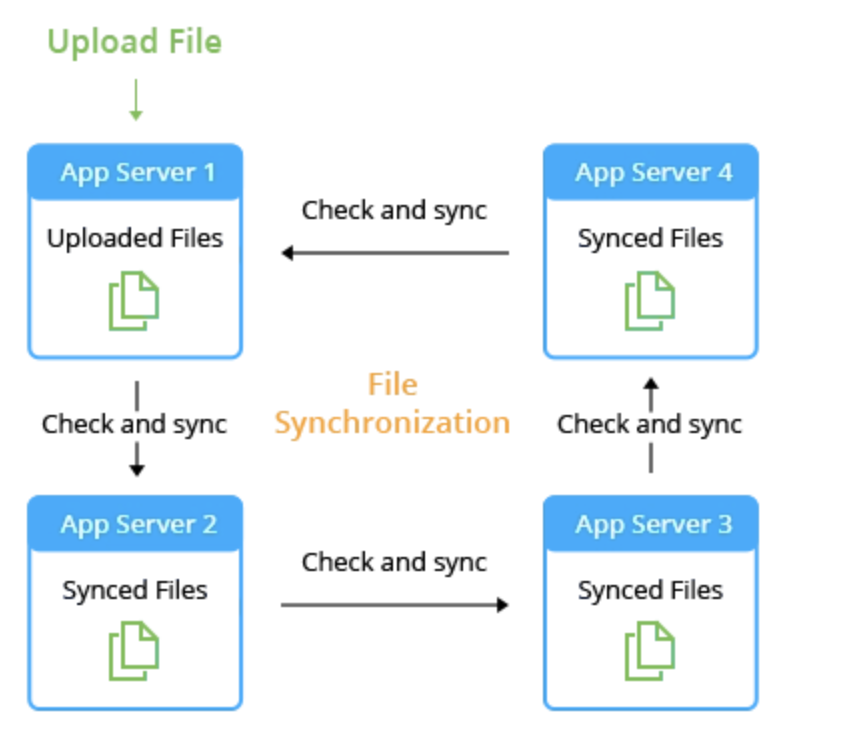
Two kinds of file transfers are necessary for file synchronization in order to preserve consistent data across many systems.
- Full-File Transfers: Entire files are copied from one location to another during full-file transfers. Although it works well, in cases where only portions of a file require frequent updates, it may consume excessive amounts of network resources.
- Incremental File Transfers: This problem is resolved by incremental file transfers, which update only the altered parts of a file. Data on portable devices like external hard drives and flash drives can be updated with the help of file synchronization services.
2. Distributed File Systems
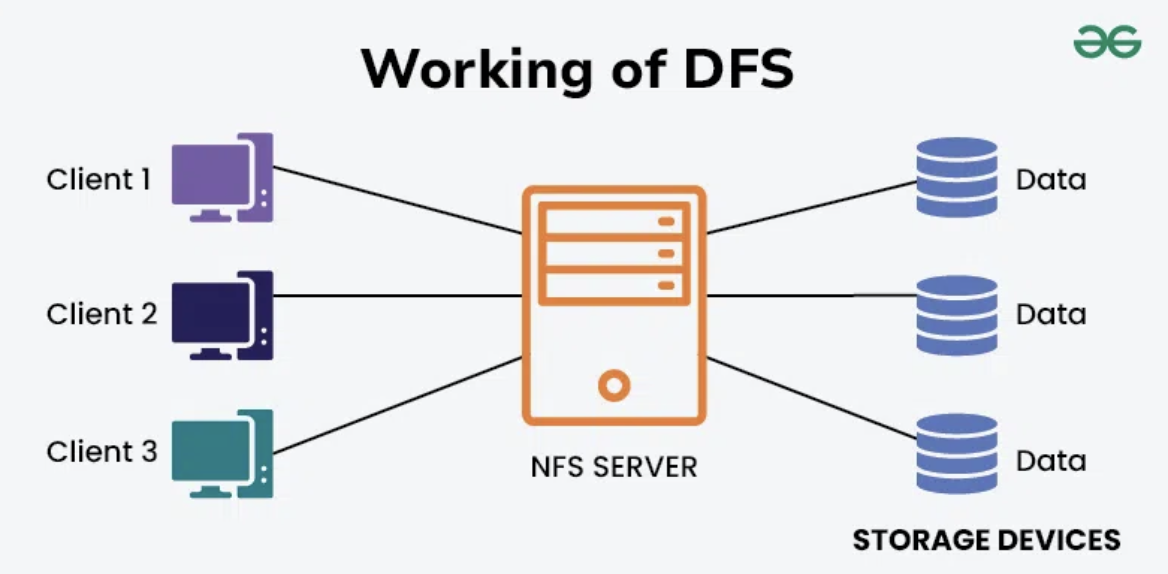
A distributed file system (DFS) uses a single, unified namespace and authoritative copies of data files to preserve data harmonisation even while it distributes its storage architecture across numerous nodes, file servers, and locations.
- With files split up and dispersed among the nodes, each DFS node normally hosts a portion of the full file system.
- Regardless of the data’s actual location, users can access files and directories as though they were kept on a single system.
- File synchronization in a DFS is only possible between systems that are actively connected to the network and have the necessary network privileges.
- DFSs are particularly helpful for syncing and exchanging read-only items, such as product catalogs.
3. Version Control Systems
Multiple contributors can work on a group of files or documents using version control, which tracks changes and maintains a history of revisions. This method makes it easier for synchronization programs to handle data files that need numerous users to update them at once.
- Edits can be made independently by each user without interfering with the work of others.
- Maintaining a single, up-to-date version of a file is the goal of version control systems, or VCSs.
4. Database Synchronization
Database synchronization is the process of copying data between databases and other tabular data components.
There are four main steps involved in database synchronisation.
- Insert synchronization: By matching primary key values, insert synchronization transfers database records from a source database to destination databases.
- Drop synchronization: The reverse of insert syncing, drop synchronization eliminates data records from target databases when they are deleted from the source.
- Update synchronization: It facilitates the propagation of changes from the source database to the target databases.
- Mixed synchronization: This method automates database synchronization by combining insert, drop, and update synchronizing.
5. Data mirroring
Data mirroring, sometimes referred to as mirror computing, makes identical copies of data, or mirrors, and keeps them on different storage media across several systems in various places. The secondary systems that store the mirrored copies instantly receive any changes made to the original system.
Types of Data Synchronization
1. One-Way Synchronization
A target system is updated using one-way synchronization, also known as unidirectional synchronization, in response to modifications made to a source system.
- Changes move from source to target without returning to the source, and data is copied from the source place to the target location.
- For data backup and distribution duties, including moving material from origin servers to edge servers in a content delivery network (CDN) and synchronizing local files to cloud storage, one-way syncing is frequently utilized.

2. Two-Way Synchronization
Changes made to either the source or destination dataset are transferred to the other component when two-way synchronization is used.
- Regardless of which component started the sync, data goes both ways, enabling changes in one system to be mirrored in the other.
- Two-way sync is frequently utilized in settings where data can be changed from several sources, which makes it ideal for synchronizing tasks in group applications (such as synchronizing contacts or calendars between devices).

3. Multiple-Way Synchronization
Any system can provide updates because of multi-way synchronization, which allows many systems to serve as sources of truth.
- Multiple source systems can make updates at once, and any machine on the network can write modifications and spread them to the others.
- In distributed contexts, multi-way synchronization is frequently used to effectively synchronize data across international applications.
- Multi-way sync is helpful for syncing files in cloud-based storage services (like Dropbox) since it allows users to synchronise data in several locations inside the same data file.
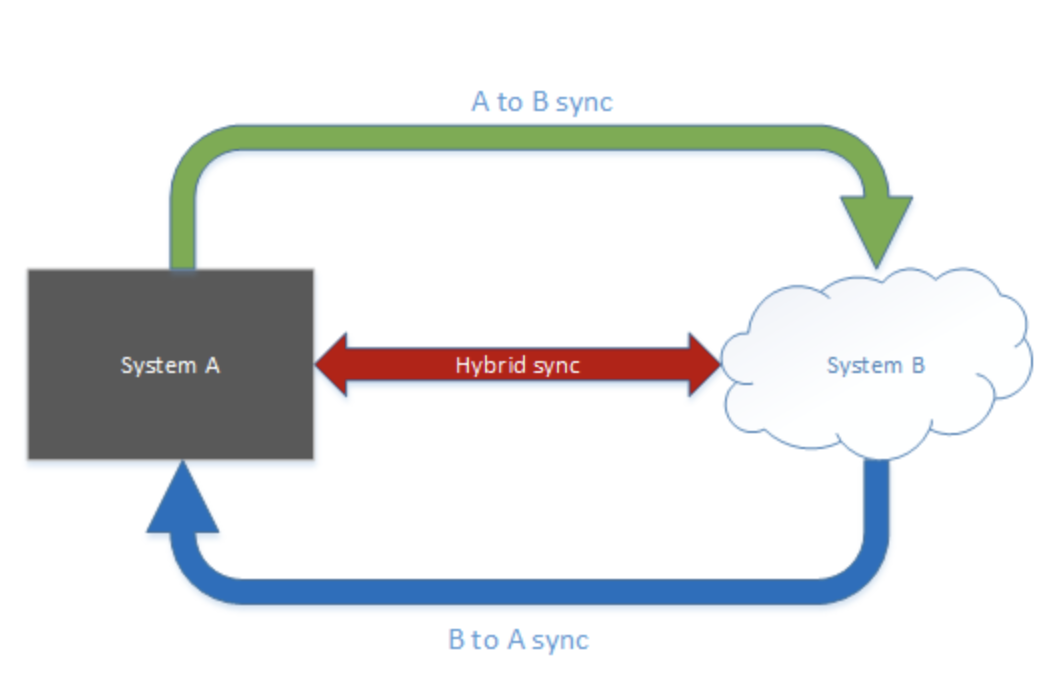
4. Hybrid Synchronization
In hybrid computing systems, hybrid synchronization effortlessly reconciles data from several sources, such as data lakes and warehouses. Because hybrid architectures integrate data from public and private clouds, on-premises data centres, and a variety of data platforms, synchronization becomes particularly challenging.
- One example is SQL data synchronization. Across cloud and on-premises sync groups (the collection of databases selected for synchronization in a certain data transfer or exchange), SQL data sync allows teams to alter data in both directions.
Real-time vs Batch Data Synchronization: When to Use Which?
| Real-time Data Synchronization | Batch Data Synchronization |
| To ensure that users throughout the network have access to the most recent information, real-time synchronization instantly reconciles data modifications as they happen in the origin system. | Asynchronous data updates, often known as batch synchronization, involve gathering changes over time and applying them all at once. |
| To control the data transmission process, IT teams can utilize an extract, transform, load (ETL) tool or a web-based or local file transfer technique. | Updates minimise the effect on system resources during periods of high demand by happening at regular, predetermined intervals, such as hourly or nightly. Depending on certain system occurrences, IT staff occasionally manually initiate system updates. |
| Updates to time-sensitive services, such as online banking platforms, video conferencing tools, and live data feeds (stock trading tools, for instance), are commonly made via real-time synchronization. | Batch synchronization is ideal for jobs that either don’t require time sensitivity (like database backups) or when real-time updates aren’t practical. |
How Does Data Synchronization Work?
Step 1: Observing changes in the data is the first step. An update event is triggered when you make changes to the customer data in a database. The data synchronization procedure begins as soon as a change is noticed.
Step 2: The goal of synchronization is to identify the discrepancies rather than to replicate everything. When changes are made, the procedure isolates those instances.
Step 3: Once the changes have been identified, the sync procedure starts to move data. It may employ synchronous or asynchronous approaches.
Step 4: It is necessary to perform a data transformation on the incoming data when it is not in the same format as the data that is already at the destination. It entails cleaning up the data and ensuring that it matches the intended data set.
Step 5: Now, the next step is to apply changes to existing data. The sync method introduces the modifications to the target data after verifying that the data at various locations are compatible.
Step 6: Lastly, the updated system confirms that the modifications were successful. For example, an API that processes the change returns a message indicating that it was successful. The process might attempt to resume the update or display an error message if this doesn’t occur.
What Are the Top Tools for Data Synchronization?
The top three tools are as follows:
1. Hevo: The only real-time ELT no-code data pipeline platform that can automate data pipelines that are adaptable to your demands at a reasonable cost is Hevo. With Hevo’s no-code ELT pipeline, you can swiftly load large datasets and provide analysts access to the data.
2. Apache Nifi: An open-source integration tool with a focus on synchronization is called Apache Nifi. It provides a feature for managing data transportation between several sources and destinations in almost real-time.
3. DryvIQ: It is renowned for enabling businesses to identify and move data between various systems in two-way sync. The platform specializes in large-scale system file migration and synchronization across storage platforms.
You can also explore the complete list of the top 10 data synchronization tools.
What Are Examples of Common Data Synchronizations?
- Healthcare Systems: Data synchronization is essential to healthcare systems’ ability to keep correct patient records. To synchronise patient data across departments, hospitals deploy electronic health record (EHR) systems. Doctors, nurses, and specialists can all get the same information because of this synchronization. To prevent mistakes, a patient’s medication history, for instance, needs to be the same in every department.
- Finance Industry: Data synchronization is essential for financial organizations to monitor transactions in real time. In order to rapidly update account balances across branch systems, online banking, and ATMs, banks employ synchronization. This procedure guarantees accurate financial records and avoids inconsistencies. For example, when a consumer takes out cash from an automated teller machine (ATM), their online banking app instantly displays the new balance. Because it provides real-time data for analysis, synchronization is also essential for fraud detection.
What Are the Benefits of Synchronizing Data?
Some of the key benefits are as follows:
- Ensures data consistency by keeping information accurate and up to date across all systems.
- Improves efficiency by reducing manual work through automated data updates.
- Enhances decision-making by providing reliable data for better business insights.
- Boosts collaboration by allowing teams to access the same updated data in real time.
- Reduces errors by minimizing duplication and discrepancies in data.
What Are the Main Data Synchronization Challenges?
Following are some of the main challenges:
- Data conflicts occur when different versions of the same data exist across systems.
- Network latency can cause delays in real-time synchronization, leading to outdated information.
- Scalability issues arise when handling large volumes of data across multiple platforms.
- Security risks increase when syncing sensitive data across various locations.
- Compatibility problems occur when integrating different systems with varying data formats.
Conclusion
Data consistency is provided via data synchronization, which ensures that data is consistent across different systems or locations. In order to avoid mistakes and duplication, data is inspected and cleaned as it enters the system. To help preserve the accuracy of the data record, real-time data updates are done across all systems. Data synchronization can be accomplished in a variety of ways, each with special advantages and possible drawbacks. The process can be streamlined and outcomes can be enhanced by acknowledging these factors and using the appropriate instruments.
Choosing the right tools can simplify synchronization and improve results. Hevo automates this process, providing seamless, real-time data synchronization without manual effort. With its no-code platform, you can ensure data consistency effortlessly. Sign up for a 14-day free trial and experience Hevo’s unbeatable pricing while streamlining your data management with ease.
FAQs
1. What is meant by synchronization of data?
Synchronization of data is the process of ensuring that data remains consistent and up to date across multiple systems, databases, or devices.
2. What is an example of data sync?
An example of data sync is when a cloud storage service like Google Drive updates a file across all linked devices after a change is made.
3. What is the purpose of synchronization?
The purpose of data synchronization is to maintain data accuracy, consistency, and reliability across multiple locations, enabling seamless access and integration.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





