

Nowadays, many organizations use a large volume of data regularly. Fast retrieval of this data is as important as the accuracy of data. Traditional databases are fine to use when data is not that large, but using it for large amounts of data is not a good option as it results. In order to handle vast datasets, it is better to use vector databases to get quick results and improved performance.
Table of Contents
This blog discusses the Pinecone vector database, what is the need for it, how it works, its features, ways to create vector databases with Pinecone, its advantages, challenges, and use cases.
Overview of Pinecone

Pinecone is a specialized Vector Database (VectorDB) made to handle and query vector embeddings, which are frequently utilized in machine learning and artificial intelligence applications such as generative AI, recommendations, and semantic search. Fast similarity search over high-dimensional vectors is made possible, which is crucial for applications that use embeddings from large language models (LLMs) to find the vectors that are most similar to a query vector.
Learn how data governance tools like Collibra can complement Pinecone’s capabilities in managing vector data
What Is a Pinecone Vector Database?
Pinecone is a managed vector database platform designed specifically to address the difficulties of high-dimensional data. Pinecone’s state-of-the-art indexing and search features enable data scientists and engineers to build and deploy extensive machine learning systems that efficiently handle and evaluate high-dimensional data. Users may store and index new data as it becomes available without any disruptions or downtime because of Pinecone’s seamless support for real-time data intake.
What Is the Need for Vector Databases?
- Currently, we are in the AI revolution. It promises fantastic advancements and is upending each industry, but it also brings with it new difficulties. For applications involving massive language models, generative AI, and semantic search, efficient data processing is now more important than ever. For these purposes, relying on traditional databases is slow and ineffective, while vector databases are lifesavers.
- Vector embeddings, a kind of vector data representation, are the foundation of all these new applications. They contain semantic information that is essential for the AI to comprehend and retain a long-term memory that it may use to complete challenging tasks.
- AI models (such as large language models) create embeddings, which are difficult to handle due to their numerous properties and features. These characteristics represent various aspects of the data that are crucial for comprehending correlations, patterns, and underlying structures in artificial intelligence and machine learning. This is why we require a dedicated database made especially to handle this kind of data.
These needs are met by vector databases such as Pinecone, which provide optimal embedding storage and querying capabilities. Apart from being slow retrieval, standard scalar-based databases lack the specialized ability to deal with vector embeddings. Vector databases possess the capabilities of a standard database that are lacking in standalone vector indexes.
Explore how building a strong metadata management framework can enhance the performance of your Pinecone vector database.
How Does Pinecone Work?
An Approximate Nearest Neighbour (ANN) search is performed by a vector database using a variety of algorithms. These algorithms use graph-based search, quantization, or hashing to optimise the search. These algorithms are combined to create a pipeline that retrieves a query vector’s neighbours quickly and accurately. The primary trade-offs we take into account are between accuracy and speed because the vector database only yields approximate results. The query will be slower if the result is more accurate. A good system, however, can offer extremely quick searches with almost flawless accuracy.
A typical vector database pipeline has three stages: indexing, querying, and post-processing.
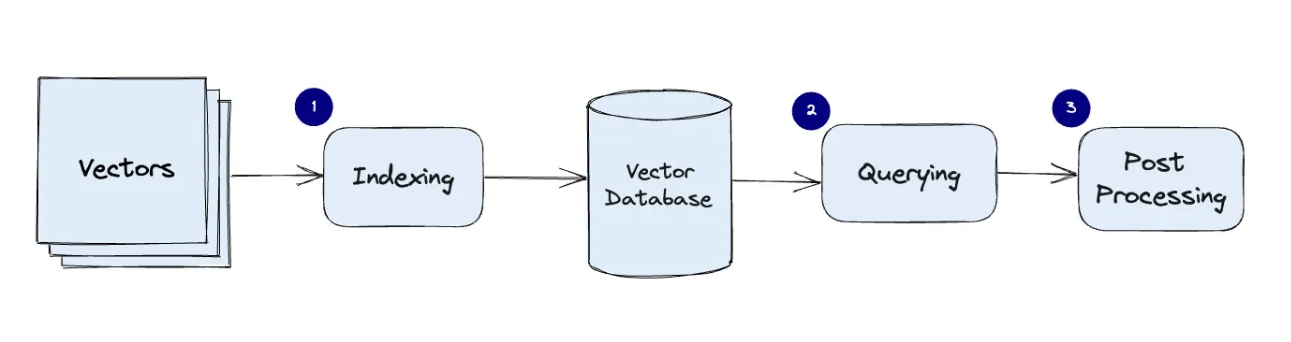
- Indexing: An algorithm like PQ or HNSW is used by the vector database to index vectors. In order to facilitate quicker searching, this phase converts the vectors to a data structure.
- Querying: Using a similarity measure that the index uses, the vector database finds the closest neighbours by comparing the indexed query vector to the indexed vectors in the dataset.
- Post-Processing: To return the final results, the vector database occasionally extracts the dataset’s final nearest neighbours and post-processes them. Reranking the closest neighbours using an alternative similarity metric may be part of this stage.
Data vault modeling can play a crucial role in scaling your Pinecone setup for better data organization and accessibility.
What Are the Features of Pinecone?
To improve search capabilities in high-dimensional data, the Pinecone Vector Database provides a number of features. Some of them are as follows:
- Provides Fast and Scalable Search: Pinecone is built for speed. It finds similar vectors in milliseconds, even across millions of data points.
- Fully Managed and Hassle-Free: No servers to set up, no scaling headaches. Pinecone handles everything behind the scenes.
- Provides Hybrid Search for Better Results: It mixes keyword-based search with AI-powered vector search to get the best of both worlds.
- Very Easy to Integrate: With just a few lines of code, making it great for developers.
- Built for AI and Machine Learning: It is perfect for powering recommendation systems, AI search, and Retrieval-Augmented Generation (RAG).
What Are the Ways to Create Vector Databases with Pinecone?
You can start by logging in to the Pinecone console. There, you can obtain a Pinecone API key, which is required to use Pinecone from Python.
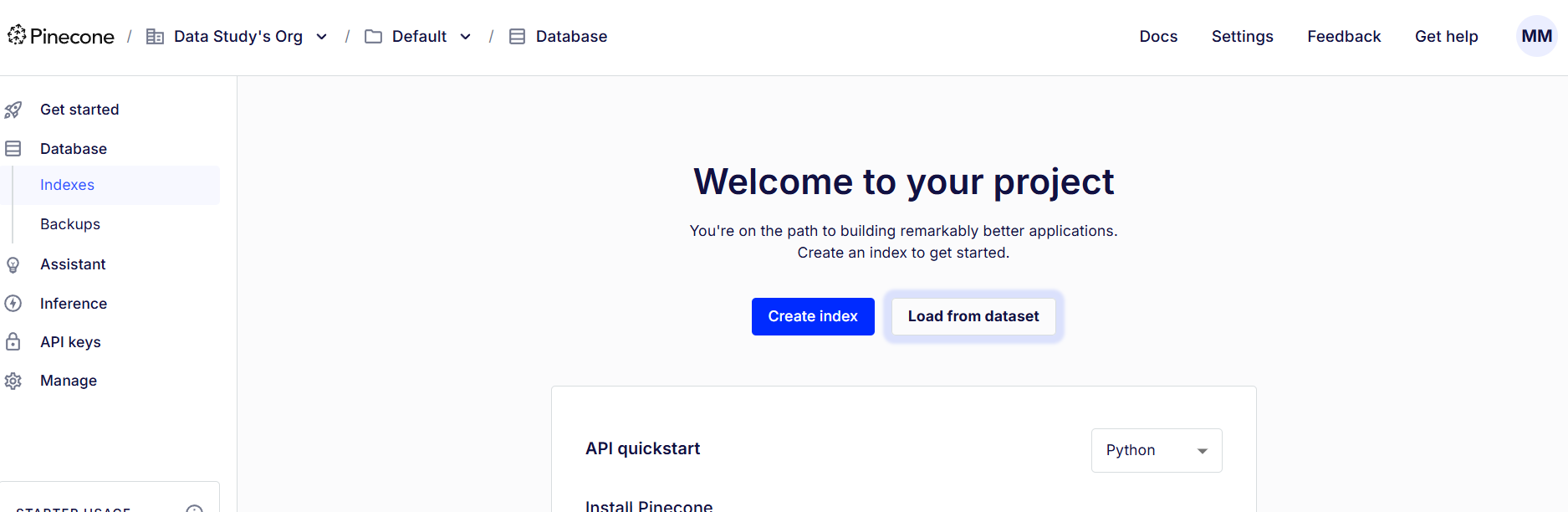
To find your API key, go to the Pinecone console and, from the left-hand side, choose “API Keys.” You can view your default API key and create a new one there.
Now install python Client for python using this pip command:
pip install pineconeOnce you have your Pinecone API key and Pinecone installed in your system, the next step is to initialize Pinecone using that API key.
# Import the Pinecone library
from pinecone import Pinecone, ServerlessSpec
# Initialize a Pinecone client with your API key
pc = Pinecone(api_key="*******")After this, create a Pinecone Index. An index is where vectors are stored. You can think of it as a table in a database. Using the following commands, you can add three 5-dimensional vectors into your index.
pc.create_index(
name="sampleindex",
dimension=5,
metric="euclidean",
spec=ServerlessSpec(
cloud="aws",
region="us-east-1"
),
deletion_protection="disabled",
tags={
"environment": "development"
}
)To add vectors to the index, we can use upsert. The upsert operation either adds a new vector to the index or updates an existing vector if a vector with the same ID already exists. Here, we are adding three 5-dimensional vectors: Ben, Jerry, and Tom.
index = pc.Index("sampleindex")
index.upsert([
("Ben", [0.4, 0.4, 0.4, 0.4, 0.4]),
("Jerry", [0.2, 0.2, 0.2, 0.2, 0.2]),
("Tom", [0.5, 0.5, 0.5, 0.5, 0.5])
])Now, let’s check the stats of this index:
index.describe_index_stats()It returns this:
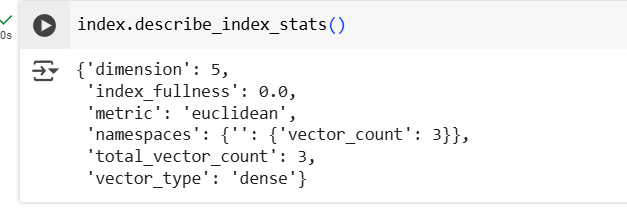
This gives details about the index, its dimension, metric, and some other details.
Let’s query this index. We will give it a vector to query and specify that we need to see the top 2 matches.
index.query(
vector=[0.5, 0.5, 0.5, 0.5, 0.5],
top_k=2,
include_values=True
)It returns this:

It has returned Tom and Ben as the top two best matches to our queried sample vector.
Improving data quality ensures Pinecone’s vector database works with the most accurate and reliable information.
Advantages of Using Pinecone
There are various benefits of using Pinecone. Some of them are as follows:
- Pinecone saves so much time. It finds similar vectors within milliseconds, even with massive datasets.
- You do not need to worry about servers or scaling. Pinecone handles servers, indexing, or scaling.
- It combines an AI-powered vector search with keyword filtering for better precision.
- It has a simple API, so it is easy to connect with AI models and applications.
- It is ideal for retrieval-augmented generation (RAG), recommendation systems, and semantic search.
- It provides built-in encryption, access controls, and cloud support to ensure data safety and uptime.
What Are the Challenges Using Pinecone
Even though there are several benefits to using Pinecone, there are also some challenges. Following are some of those challenges:
- The free version of Pinecone is fine for basic functionality, but a paid version is required for more computational power and storage. The pricing can get high as your dataset grows and search queries increase.
- Data preparation for Pinecone can be a bit tricky. Converting raw data into vectors requires extra tools and knowledge of embedding models.
- Pinecone is a managed service. Therefore, it offers less control and customizations as compared to self-hosted solutions.
- It has some scalability issues, such as extremely large datasets may face performance trade-offs, especially with high-dimensional vectors.
- Learning it is complex, and it can be challenging for those unfamiliar with vector databases and AI search technologies.
Data cleansing through SQL is essential for maintaining clean data before loading it into Pinecone for optimal use.
What Are the Use Cases of Pinecone Vector Database?
Here are some of the use cases of the Pinecone vector database:
- Chatbots: When there are specialised or exclusive requirements, chatbots trained on the AI models can create and offer extremely relevant responses. They have access to long-term memory of a vector database like Pinecone. These AI-powered chatbots are used by businesses for a range of purposes. For example, you might have seen shopping assistants, who can enhance the customer experience by assisting customers in navigating the website more effectively, perusing the product offers, and finding what they’re looking for.
- Semantic search: Semantic search makes advantage of the search query’s meaning. Create and offer a solution that will improve the relevancy of search results for end users to obtain a competitive edge. Users will be able to find solutions to their enquiries more quickly, thanks to semantic search, which will boost productivity. For instance, Pinecone is used by a multinational ERP software business to enable its clients to obtain insights from employee feedback through semantic search.
Conclusion
Vector databases provide a specialized solution for effectively handling high-dimensional data, which is becoming increasingly important, especially in fields of machine learning, data science, and AI-driven applications. Its scalability, low-latency search capabilities, and real-time data intake are the key highlights of Pinecone.
It is a managed vector database platform that is particularly useful for data scientists and engineers. You can use the free version to try Pinecone and build basic applications with limited storage. If you need more storage and computation, you can choose paid plans. Pinecone simplifies the process of developing and implementing extensive machine learning applications with its smooth integration and intuitive API.
To enhance your Pinecone experience, seamlessly integrate your data with Hevo’s no-code platform, which automates data pipelines and enables real-time data loading into Pinecone. Sign up for a 14-day free trial with Hevo today and streamline your data integration process to unlock the full potential of your vector database applications.
FAQs
1. Is the Pinecone vector database free?
Yes, Pinecone offers a free plan with limitations on storage and compute. This can be helpful for developers to experiment and build small-scale applications. But for more storage and computation power, it’s important to upgrade to a paid plan.
2. What is the difference between Pinecone and Elasticsearch?
Pinecone:
1. Pinecone is based on an Approximate Nearest Neighbor (ANN) search.
2. This vector database is suitable when you have to search for matching data points through massive datasets.
3. Pinecone cannot do reads and writes in parallel, hence, writing in large batches can affect query latency and vice versa.
Elastic Search:
1. Elasticsearch uses the inverted index as its data structure.
2. Elasticsearch analyzes massive amounts of text data (full-text data and keyword search) and structured data rapidly.
3. Elasticsearch facilitates bulk intake and updates.
3. What is a vector database in simple terms?
A vector database is a specialized database that stores vector embeddings (mathematical representations of data). It allows fast similarity search. In traditional databases, we can search exact matches, but vector databases find the most similar items based on closeness in multidimensional space.
For example, if we upload an image of a flower, a vector database can quickly find similar flower images based on features like shape and color.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





