

Data-driven decision-making requires dimensional data modeling. McKinsey says data models can boost operational profitability by 60%. High-quality data modeling is crucial to staying ahead in the competitive market, according to this research. Modern corporate intelligence and analytical reporting systems rely on data modeling. This technology simplifies data extraction and query execution to swiftly and effectively draw insights. You may know relational data models. They excel in transactional systems that prioritize data consistency. Dimensional models simplify design, accelerate reporting, and make data easier to browse for analytical purposes.
Table of Contents
This blog will cover dimensional data modeling—what it is, why it’s important, how to design one, and its applications. After reading this, you’ll know how to use this useful tool in your data projects.
What is a Dimensional Data Model?
Dimensional data modeling is a technique to create databases that are designed for analytics and query performance. The major goal is to be able to query, report and analyze quickly.
We can break data into facts and dimensions in a dimensional model:
- Facts: Quantitative data that is used to measure business processes. Aggregated or summarized such as sales amounts
- Dimensions: Descriptive attributes that provide context for the facts, such as time, location, product, and customer.
For instance, suppose that you have a sales report:
- The facts may include the amount of sales, total sales value, or number of units sold.
- The dimensions could be “Date” or “Product Category”.
These models denormalize data which means that data is stored in fewer tables. This results in fewer joins and better query performance, contrary to relational databases that normalize data and reduce redundancy by breaking data into multiple tables.
You can take a look at the Ultimate Guide to Create Your Own Data Model.
Why is Dimensional Data Modeling Important?
- Optimized Query Performance: Dimensional models improve the performance of queries. It is extremely helpful for complex and analytical queries. Denormalizing data reduces the number of joins that is needed to be done in a query, which makes the query run faster. This is especially important for large-scale datasets often encountered in data warehousing.
- Simplified Reporting: The dimensional model’s structure is simple for business users to understand and work with. Dimensions are usually intuitive (e.g., “Region,” “Product,” “Time”), and they provide meaningful context for interpreting the facts. Analysts and decision-makers can navigate through the data with minimal technical expertise.
- Historical Data Tracking: Many business processes require tracking data over time—such as sales trends or customer behaviors. Dimensional models are excellent at capturing historical data through dimensions like “Time,” which allows businesses to observe trends and make decisions based on past performance.
- Scalability: As businesses grow and more data sources are added, it’s easy for dimensional models to add new dimensions or facts without significant restructuring. This makes sure that the model can scale as the needs of the organization grow.
- Improved Decision-Making: With easy-to-query data and simplified reporting, business leaders can quickly derive insights, leading to more informed and timely decisions. Whether it’s analyzing sales performance or understanding customer behavior, it provide a solid foundation for decision-making.
Case Study: How did Walmart leverage Dimensional Modeling?
Walmart is the biggest retailer in the world, so every day it handles millions of transactions in many areas and locations. Walmart used dimensional data modeling to organize and analyze its huge amounts of data from its shops and websites in a smart way. By implementing a data warehouse with a star schema, Walmart structured its data into fact tables (e.g., sales data, etc.) and dimension tables (e.g., date, category, product, store, customer, etc.) to improve reporting and analysis.
This approach made it easier to ask questions, better at analyzing trends, better at managing inventory and better at making decisions by giving quick access to aggregated data. In the end, this model enabled Walmart to expand its data infrastructure, make operations more efficient and help everyone in the business make better choices based on data.
Elements of Dimensional Data Modeling
- Facts: These represent the measurable quantities in the model. In an e-commerce business, a fact could be “total sales” or “number of orders.”
- Dimensions: These are descriptive elements that provide context for the facts. For example, time and date are the most popular dimensions for time series analysis. Time can be further broken down into quarter, month and year. Location (country, region) and product (category, brand) are also on the list.
- Attributes: These are specific characteristics or details of a dimension. For instance, the product dimension might include attributes like product name, product category or weight. These specifically describe the details of the dimension.
- Hierarchies: Dimensions are set up in a hierarchy, which lets you combine data at different levels of granularity. In the time dimension, you might have a structure that goes from Year to Quarter to Month to Day. Similarly for product, you can have a hierarchy that goes from Product Category to Product Sub-Category to Product Name.
- Measures: These are facts that show how activities are performing overall such as average sales or total revenue over time.
Facts vs. Dimensions
| Aspect | Facts | Dimensions |
| Definition | Quantifiable metrics | Descriptive attributes |
| Example | Sales Amount | Product name, region |
| Purpose | Measures performance | Provides context |
| Data Type | Numeric | Text or categorical |
Star Schema vs Snowflake Schema
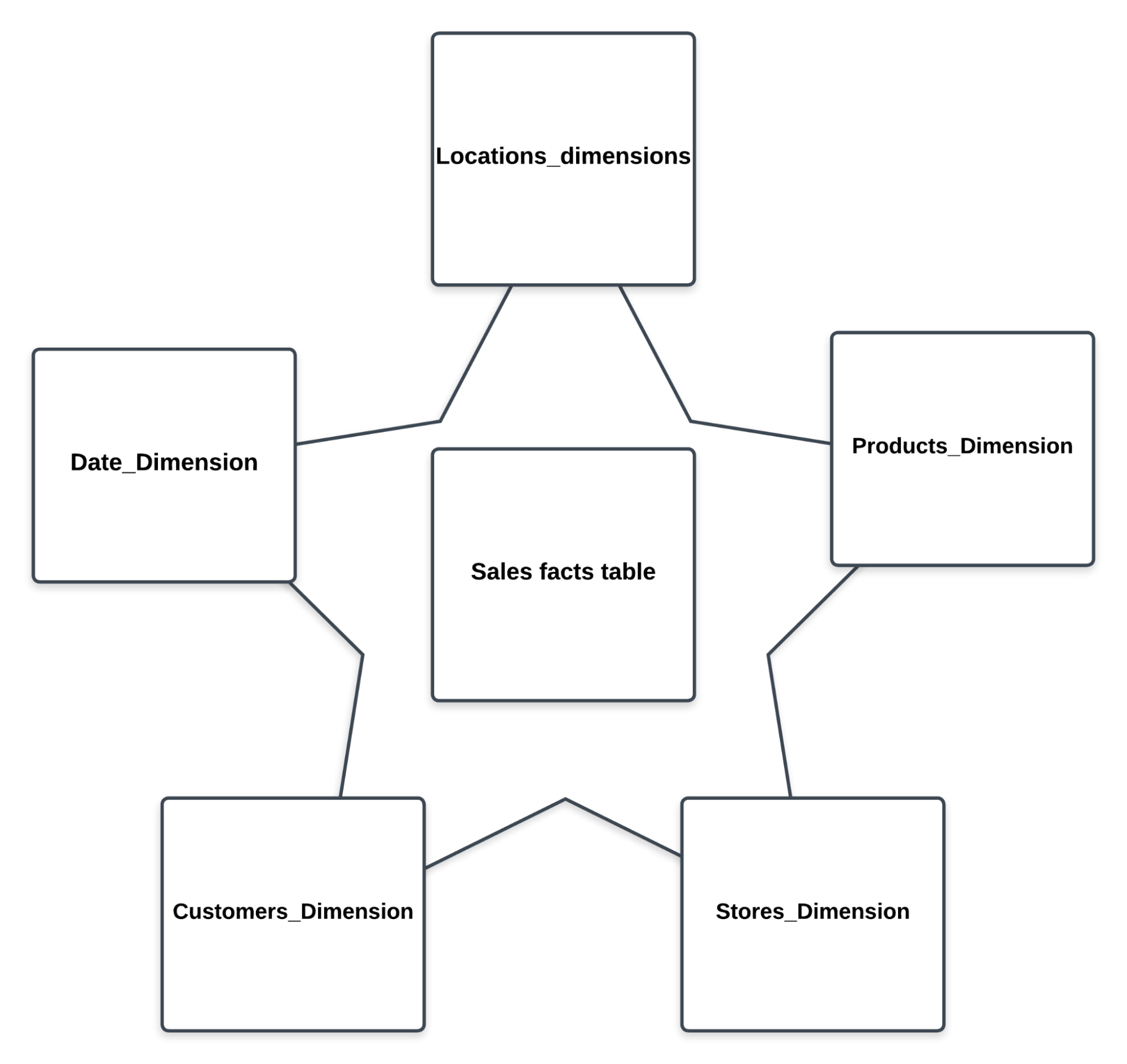
Star Schema:
Snowflake Schema:
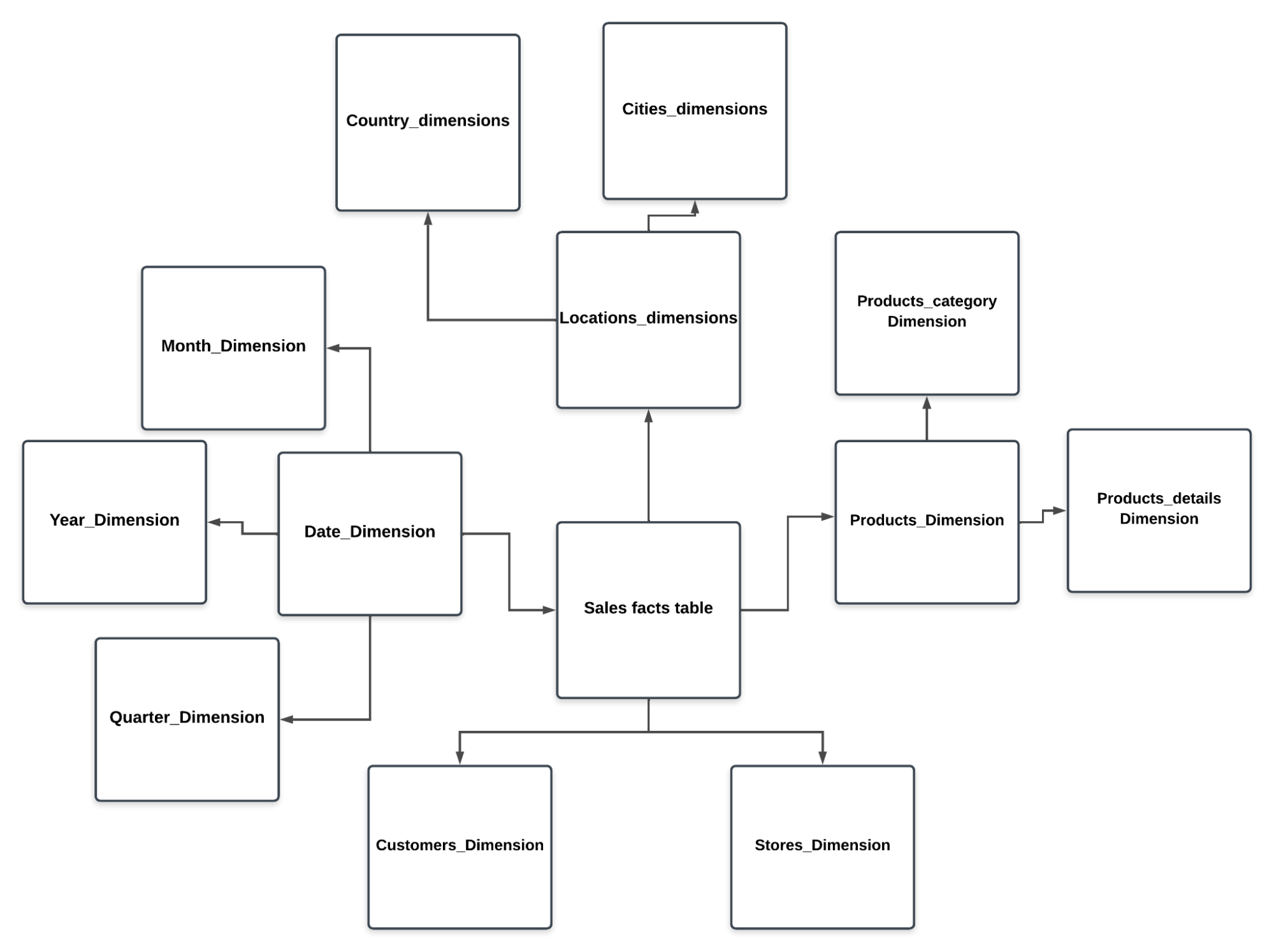
The Star Schema and Snowflake Schema are two popular ways of organizing data in a dimensional model. Here’s a comparison of both:
| Aspect | Star Schema | Snowflake Schema |
| Structure | Single-Level Dimensions | Multilevel, normalized tables |
| Complexity | Simple | Complex |
| Query Performance | Faster | Slower |
| Use Case | Ad-hoc reporting | Complex |
You can take a look at how you can easily perform data modeling in Power BI to get better insights from your data.
Types of Dimensions in Data Modeling
There are several different types of dimensions used, depending on how they are structured and the business needs they address:
- Conformed Dimensions: These dimensions are used across multiple fact tables and have the same meaning in all contexts. For example, “customer” might be a conformed dimension used in both a sales fact table and a returns fact table.
- Role-Playing Dimensions: These are dimensions that play multiple roles in a data model. A single “date” dimension, for example, could be used in multiple ways, such as “order date,” “ship date,” and “delivery date.”
- Slowly Changing Dimensions (SCDs): These are dimensions where the values change over time. For example, a customer’s address or membership status may change, but we still need to track the historical data. SCDs are critical for capturing data changes without losing previous information.
- Degenerate Dimensions: These are dimension keys that are stored in the fact table but don’t have corresponding attributes in a dimension table. For example, an “Invoice ID” might be a degenerate dimension.
- Junk Dimensions: These are collections of random attributes (like flags or status indicators) that don’t fit well into other dimensions. For example, a dimension containing “Discount Applied” and “High Priority” flags would be classified as a junk dimension.
Also, take a look at the Top 10 Data Modeling Techniques to get more out of your data.
Steps to Create Your Own Dimensional Data Model
- Understand Business Requirements
You should have a deep understanding of the business processes you are modeling. Plan and discuss with the stakeholders. Develop key performance indicators and write down the questions that the data model needs to answer.
Example: A store wants to analyze monthly sales trends by product category and region. Write questions like: “Which product sells best in a specific region?”
- Design Fact Tables
Identify the measurable processes in the business and decide the level of granularity you need for analysis.
Example: Create a Sales Fact Table that records daily sales amount, quantity sold, and store location.
- Design Dimension Tables
Design the attributes and structures for your dimension tables.
Example: A Product Dimension Table could include product name, category, brand, and price.
- Choose a Schema
Decide whether to use a star schema or a snowflake schema. For most use cases, a star schema is preferred for its simplicity and speed.
Example: Use a star schema where the Sales Fact Table connects directly to dimensions like Product, Store, and Time.
- Implement ETL Processes
Develop an ETL pipeline that extracts data, transforms into the model format and loads it into your data warehouse.
Example: Extract sales data from a CRM, transform it into the required format, and load it into the Sales Fact Table.
- Test and Validate
The model needs to be tested and validated according to the business’s reporting needs. You can query the data and make sure it gives you correct results.
Example: Query “Total sales by product category in October” and compare the result with the raw data.
Advantages of Dimensional Data Modeling
- Quicker Insights: The denormalized structure of dimensional models lets queries run faster, which makes it easier to look at big datasets and quickly come up with insights.
- Intuitive Design: The simple structure of the dimensions and facts makes it easier for business users to navigate and understand the data.
- Historical Data Tracking: Dimensional models are made to work with historical data, which makes them perfect to analyze for trends and report on time series.
- Scalable Architecture: Dimensional models can easily be adapted to accommodate new data sources and business requirements, ensuring long-term sustainability.
Challenges in Dimensional Data Modeling
- Requires High Effort: For a dimensional model to be built, it takes a lot of work to get business needs and data organized.
- Trade-off with Data Redundancy: Denormalization can speed up queries but it can also lead to data redundancy and increase storage requirements.
- Maintenance Complexity: Managing slowly changing dimensions or adapting to business changes can add complexity and require regular maintenance.
- Performance Trade-offs: When it comes to speed, Snowflake schemas may slow down queries because they have more joins, even though they are more normalized.
Real-World Use Cases
- Retail Analytics: Dimensional modeling helps stores keep track of sales data by store, area, product, vertical, and time period. This helps them make better decisions and get the most out of their inventory optimization.
- Healthcare Analytics: Hospitals track patient metrics by age, treatment type and region. It facilitates best practices and improves the quality of patient care.
- E-commerce Analytics: Marketplaces analyze customer behavior across product categories and regions. This helps in improving their recommendation engine and marketing efforts.
- Financial Services: Dimensional models are used by banks and other financial institutions to analyze financial data and detect trends, anomalies and fraud.
Future Trends
- Hybrid Models: Businesses have started to develop hybrid models (dimensional models with relational models) to benefit from both of these approaches.
- Cloud-Based Data Warehousing: It’s getting more popular for businesses to use cloud-based platforms like Snowflake to better scale their dimensional models.
- AI-Powered Data Modeling: AI tools like dbt are automating the development of dimensional models, which makes them easier to use.
- Real-Time Analytics: Businesses can use Apache Kafka to set up dimensional models in real-time.
Conclusion
Dimensional data modeling is an excellent approach for businesses to organize and analyze data quickly. It offers better scalability, streamlined reporting, and quicker searches. It denormalizes the data and breaks it down into facts and dimensions. Dimensional modeling shall remain a key component of effective business intelligence strategies as the field of data analytics changes with new evolving technologies such as cloud computing, artificial intelligence and real-time data processing. It is also important for transforming data into useful insights, whether you want to speed up reports, make trend analysis easier, or make better business decisions.
Try a 14-day free trial and experience the feature-rich Hevo suite firsthand. Also, check out our unbeatable pricing to choose the best plan for your organization.
Frequently Asked Questions
1. What is the difference between relational and dimensional modeling?
The difference comes into the focus. Relational modeling focuses on consistency and redundancy reduction. On the other hand, dimensional modeling focuses on simplicity and performance over normalization. It is optimized for querying and reporting.
2. What is an example of dimensional data?
In a retail store, sales data may contain facts and dimensions. Facts could be total sales or total profit while dimensions may include time or product type.
3. Is a dimensional model denormalized?
Yes absolutely! Dimensional models are often denormalized to make queries run faster. This takes up more space but it makes querying easier.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




