At some point, we have all spent hours sifting through folders and spreadsheets, searching for a data asset for our project. Sometimes, you reach a point in your data-driven journey for an organization where you require a tool to explore data, find insights, govern the data better, and manage the regulations a bit more.
Table of Contents
The solution to this problem is a data catalog. In this blog, we will discuss what is a data catalog, key components of data catalog and its use cases and benefits for data teams.
What is a Data Catalog?
A data catalog is a tool that brings together metadata from a diverse set of data assets. It creates an end-to-end searchable map of your data estate. It helps you search, discover, understand, and trust your data. It is like Google Search for enterprise data assets. A data catalog helps maintain an inventory of data assets and provides context to help users get value from the data they find. It is like indexing the metadata. By embedding data quality rules into the data catalog, businesses can automate checks for consistency and accuracy, improving data governance and user confidence.
Data catalogs have primarily been used by data professionals such as data analysts, data engineers, and data scientists. However, in today’s distributed work environment, everyone in an organization, including business users, needs context about the data metrics to make decisions.
Hevo Data is the only no-code platform that lets you connect data from 150+ sources to a destination of your choice. With Hevo, you can:
- Sync your historical data
- Automatically map your tables and columns
- In-flight data transformation
Keep your data catalog up-to-date and accurate with Hevo’s seamless data integration. Start your 14-day free trial today and empower your team to make data-driven decisions.
Get Started with Hevo for FreeWhy Should You Use a Data Catalog?
- It can save you time by providing a centralized view of all your data assets without needing to search through multiple sources or being directed to different people on your team.
- It can improve trust in your data. It ensures that the data has proper context and clearly defined business metrics.
- It encourages collaboration by forming a unified layer that integrates multiple tools across your data stack.
Not all data catalogs are created equal. When choosing a data catalog, it is essential to look for capabilities that are on par with the future of metadata management.
If a business user is looking at a dashboard and wants to know whether he/she can trust the data or find the meaning of a metric, then it is not feasible for them to switch to a different tool and search for that dashboard just to get context. A modern data catalog gives you the context as part of your daily workflows. In summary, a modern data catalog is an active metadata platform that has capabilities far greater than those of traditional catalogs. It activates your metadata and also leverages AI and LLMs to revolutionize how data teams work with their data. Integrating robust data architecture principles with your data catalog ensures seamless context and trust in the data, enhancing the overall data management experience.
In this blog, we will explore the critical role of data catalogs in modern data management, highlighting how they enhance data discovery, governance, and collaboration. We will also have a glimpse of some use cases of data catalogs in businesses.
Streamline data organization with an intelligent AI-powered data catalog for efficient metadata management and improved accessibility.
What is Metadata?
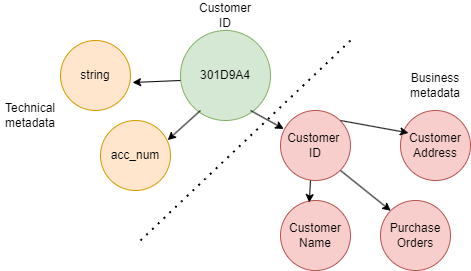
Metadata is the information about data. The types of metadata can be technical or business metadata. For example, in the below diagram, we have a Customer ID: ‘301D9A4’. The technical metadata around this Customer ID might be what type of data it is (string) or the name of the table in which the data resides (acc_num). This information gives you technical details of the Customer ID.
However, businesses are interested in business metadata. They are interested in the metadata that provides meaningful insights for the business. Business Intelligence (BI) tools are used to associate specific business definitions to the data. Operational metadata is also a type of metadata that gives information about the DQ metrics or details about the job or batch runtime.
Exploring Data Catalog Metadata
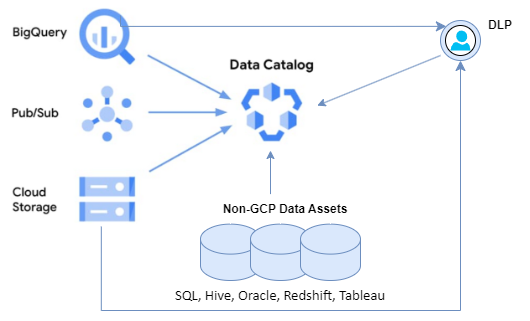
The Data Catalog automatically synchronizes the technical metadata from data sources like Cloud Storage and BigQuery. If you create a table in BigQuery, the table shows up in the data catalog in near real-time.
Auto-tagging of PII (Personally Identifiable Information) data through data catalog integration with DLP (Data Loss Prevention). The column names in the table don’t let on as to whether it has PII data or not. The integration with DLP helps you identify and scan the data. DLP puts semantics on the data, for example, it can identify credit card numbers or social security numbers, which helps detect PII data automatically.
As shown in the below diagram, metadata often needs to be ingested from disparate data sources like SQL, Hive, Oracle, Redshift, and so on. Data Catalog provides open-source connectors that are easily accessible to all users on GitHub. It also helps ingest technical metadata from BI tools like Tableau.
Key Components and Features of a Data Catalog
The following are key components of a Data Catalog explained in brief:
Metadata Management
This is the core of the data catalog and the specific audience is IT. The inventory of data assets is created here and each asset’s lifecycle is maintained. Metadata management also addresses discovering all the data relationships physically and logically. It discovers physical relationships in data such as tables in a database and logical relationships when processes combine datasets, or semantic relationships when two data assets deal with the same business concept.
You need metadata management because the data inventory is not static. New tables are created, files are ingested, and schemas change frequently. This could potentially disrupt or cause failures in the data pipelines. So, implementing configuration management and impact analysis proves to be helpful.
Search and Discovery Tools
A data catalog should be capable of crowdsourcing knowledge through comments, ratings, reviews, and other contributions. A lot of the end users of a data catalog are subject matter experts, so capturing their insights will help enrich the data capital. “Relevance” is based on the actions of the community, which is why search and discovery tools are crucial features of a data catalog.
Here are a few data catalog and discovery tools:
- AWS Glue Data Catalog
- IBM Watson Knowledge Catalog
- Google Cloud Data Catalog
- Apache Atlas
- Oracle Enterprise Metadata Management
Data Lineage Tracking
Data Lineage is a powerful capability in the data catalog. It establishes lineage to see how the data flows from the source to your BI tools. In case of any dashboard issues, data lineage helps you identify the data flow and diagnose the problem quickly instead of sifting through SQL scripts.
So, the root cause analysis that a data engineer may go through is enabled significantly by data lineage tracking. The lineage is good for root cause analysis and proactive impact analysis. For example, a data engineer is about to make a few changes to the data pipeline and push the changes into production. The metadata that creates a lineage is used in GitHub processes to create automated alerts when you make changes.
Access Control and Security
Data products and access control go hand in hand. Access control in a data catalog is a data security process that helps organizations manage and regulate authorized access to corporate data and resources. Secure access control uses policies to authenticate user identities and ensure that appropriate control access levels are granted to users. To enhance data security, an effective data catalog should include features like a business glossary and robust metadata management. As Gartner emphasizes, a strong data governance program provides the foundation for secure, compliant, and efficient data management, supporting business agility and risk mitigation.
Collaboration and Social Features
Collaboration has to be an integral part of data governance framework and application to create an effective data governance and culture. Without collaboration, the work of individuals who have formal accountability for data in an organization, known as data stewards, is often duplicated. Also, as we discussed earlier, many data catalog end users are subject matter experts, and capturing their insights through social features like comments, ratings, and reviews is key to enriching the data capital. As remote work has become more common, collaboration has become even more crucial to data discovery and protection. Effective collaboration ensures that each contributor works toward a common goal of facilitating more comprehensive data governance.
You can also take a look at our detailed comparison of data governance vs data catalog to understand their roles in managing and organizing data effectively.
Business Benefits of Implementing a Data Catalog
Use Cases
Let us consider the Airbnb Data Catalog. Airbnb Data Catalog, known as the Data portal, has four primary features, which include:
- Search: Offers a clean, Google-like search experience for quick and efficient data retrieval.
- Context and Metadata: Provides detailed metadata, including data creators, consumers, and update timestamps, along with data lineage for understanding relationships between datasets.
- Employee-centric Data: Focuses on making data relevant to individual employees.
- Team-centric Data: Facilitates access to data pertinent to specific teams, enhancing collaboration and data management.
These features collectively enhance data discovery, contextual understanding, and collaboration at Airbnb.
The following are generalized benefits of implementing a Data Catalog for businesses:
- Enhanced data discovery and access efficiency
- Improved collaboration and innovation
- Enhanced data quality and governance for better decision-making
- Robust data security and compliance management
- Accelerated data preparation and analysis for competitive advantage
- Resource optimization and cost reduction
- Easy data integration and migration
You can check out: Data Catalog Best Practices for effective data management in your organization.
Conclusion
A data catalog is an essential tool for organizations seeking to unlock the full potential of their data assets. By providing a centralized view, enhancing data discovery, and improving governance, data catalogs empower teams to make informed decisions and drive innovation.
Hevo Data can further simplify your data management efforts by automating data pipelines and providing a robust data integration platform. With Hevo, you can easily connect to various data sources, transform data, and load it into your data warehouse or data lake.
Ready to revolutionize your data management? Explore Hevo today and discover how our ETL platform can transform your organization. Book a personalized demo with us.
FAQ on Data Catalog
1. What is the difference between metadata and data catalog?
Metadata is information that describes data. A data catalog acts like an index that organizes and indexes the metadata, making it easier for users to discover and manage data assets within an organization.
2. What is a data catalog vs a data dictionary?
A data catalog is a comprehensive tool that organizes and manages metadata across an organization’s data assets, enabling easy discovery and governance. On the other hand, a data dictionary is a more focused resource that defines and describes the structure, fields, and attributes of specific data elements within a database.
3. Do you need a data catalog?
You need a data catalog if your organization often needs to ingest metadata from disparate data sources, and a centralized system is required to efficiently discover, manage, and govern data assets.
4. Who uses a data Catalogue?
Internal IT users who need to cope with metadata management.
Governance users are okay with the data being consumed by everyone, but only if they can govern it.
End users can be any employee who wants to find the data they are looking for, understand it, and trust it.
5. What is the difference between a database and a data catalog?
A database is a system mainly used for data storage, retrieval, and manipulation. A data catalog, on the other hand, is a tool that organizes and indexes metadata from various data sources, enabling users to discover, understand, and govern data assets across the organization.
6. What is the difference between data inventory and data catalog?
A data inventory is an essential list of all data assets within an organization, which has details like where the data is stored. A data catalog goes further by organizing, indexing, and providing rich metadata, search capabilities, and governance features to help users utilize the data assets effectively.
7. What is the difference between data discovery and data catalog?
A data catalog organizes and centralizes metadata, enabling users to discover and manage data assets. Data discovery is the process of finding and analyzing data within those cataloged assets. The catalog provides the structure that makes discovery more effective.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link