

Data Lineage is crucial in data management which traces the complete data flow from the source to its destination. It is the foundational element of effective data management to ensure compliance, integrity, scalability, and security throughout the data lifecycle. By linking data elements with their definitions, data dictionary tools support comprehensive data lineage, enabling better visibility and management of data flow.
Table of Contents
In this article, we will begin by exploring data lineage, followed by its various types and significance. We will then delve into how data lineage works, discussing techniques and best practices for implementing it effectively.
What is Data Lineage?
Data Lineage is tracking data from its source to its destination. All the transformations through which data went through are tracked in data lineage. In data lineage, all data sources are identified, and all processing and transformations are traced like data cleaning, filtering, modification, and combined data and its flow across various systems and applications up to the final version of the data stored in the destination.
In today’s world of data, this helps to keep track of data availability, sensitivity, quality, ownership, and governance of data. Data Lineage keeps checking on data for the following parameters:
- Check for authoritative data sources.
- Check the data quality across various lineage hops.
- Check if data violates any data governance policy.
- Check for security of business and customer information.
- Check for correct ownership of different data tables.
- Keep track of all the processes and modification data goes through.
Types of Data Lineage
There are five types of data lineage available:
1. Business Data Lineage
Business lineage digs into data used in various business process interactions. It tracks down the processes and movement of data used for business operations. It clarifies the role of the data in supporting specific business functions. It traces the data that defines the terms, policies, and technologies, business uses across the organization. It investigates data contribution in generating reports and helps in analyzing decision-making processes within the organization.
2. Operational Data Lineage
Operational lineage is also called Technical or ETL data lineage. In operational data, lineage data is traced for complete data lifecycles based on technical operations, like ETL logs, root cause analysis, impact analysis, and pipeline workflows.
3. Descriptive Data Lineage
A descriptive lineage is one created manually. In the case of the marketing report, a descriptive data lineage could be a Word document or text file that captures details about how the report was modified over time and then exported to a data warehouse.
4. Automated Data Lineage
As the name describes, automated data lineage is generated based on reports automatically by data lineage tools. Tools ensure that this information is available via data lineage when there is any change in reports, data, or any transformations happening throughout its lifecycle. Visualizations generated help stakeholders understand changes in data over time.
5. Design Data Lineage
Design lineage identifies the data, sources, and flows that lead to a particular requirement. A design lineage for a sales report would include information about which data sources were used to create the report regarding sales, customers, and their information. It tracks how sales data is added to the report every week at the scheduled time and ensures its authenticity as well.
Looking to simplify your data lineage management? Hevo is a no-code data pipeline platform that helps transfer data from various sources to destinations. With its fault-tolerant architecture, Hevo ensures your data is always secure and prevents any data loss. Hevo provides:
- 150+ pre-built connectors to seamlessly migrate data from a wide range of sources to your preferred destination.
- Compliance with GDPR, HIPAA, CCPA, and SOC 2 Type 2 certifications, ensuring the privacy and confidentiality of your data.
- Automatic schema mapping to ensure your data is correctly mapped in the destination.
- Pre-load and post-load transformational capabilities to ensure your data is always analysis-ready.
- Transparent and cost-effective pricing plans tailored to varied data needs.
Try Hevo for free today and experience seamless data management!
Why is Data Lineage Important for Business?
Data Lineage is very important for businesses and organizations for exponential growth and quick incident resolution. Understanding the upstream and downstream dependencies of our data tables allows us to immediately assess the impact, notify stakeholders, and fix data breaks if an issue occurs. Data Lineage helps businesses in the following ways:
1. Connection between Data Sources
Data Lineage helps in understanding the connection between different data sources from where data is coming and connect them properly. It enables users to comprehend the links between multiple data sources, allowing them to answer crucial questions about where their data comes from, what modifications occurred along the route, and how it is eventually used without any errors.
2. Data Consistency and Reliability
Modern companies are data-driven, so reliable and consistent data is a pillar of organizational work and growth. Data assets are subject to change over time and come from various data sources. Ensure data comes from reliable and authoritative sources, and track newly added data and changed or discarded existing data, which is what data lineage does.
You can check out how you can improve the quality of your data to ensure better consistency and reliability.
3. Data Migration
Successful and streamlined data migration is another benefit of data lineage. It guides to migration of data from one source to another securely and seamlessly with the assurance that no bad or unauthorized data is migrated into the system. Streamlined data migration and integration across various teams ensures high work efficiency and security across your business.
4. Data Governance
The data lineage stores details at a granular level which is useful for compliance auditing, risk management, and ensuring data is stored and processed according to organizational rules and regulatory standards. Data lineage can easily highlight areas of potential risk and non-compliance with internal or external regulatory data governance policies. In alignment with Gartner’s data governance frameworks, data lineage allows for in-depth auditing and risk assessment, providing an essential view into data compliance and regulatory adherence.
5. Data-Driven Decision Making
A data lineage diagram helps in understanding the connection between data, its complexity, and detailed analysis. It contains all the information regarding assets, their users, and authorities, which helps in making important influence decisions. Outdated assets are depreciated to avoid potential issues and help businesses focus on growth and quality.
How did Data Lineage work?
In today’s world, there are many data lineage tools like OpenMetadata, Apache Atlas, Informatica Metadata Manager, Manta, Alation, and many more that provide instant visibility of the transformation and journey of data. It ensures a smooth transition of data from source to destination, and in case of error, it is easy to debug and analyze to find the root cause of the problem using data lineage tools.
The best data lineage practices take all eight phases of the data lifecycle into consideration:
- Data Generation
- Data Collection from internal and external sources.
- Raw Data Processing
- Data Storage
- Data Management
- Data Analysis
- Data Visualization
- Data Interpretation
In the data lifecycle, data is reused in multiple branches for different purposes. Each branch undergoes different processing, storage, management, analysis, visualization, and interpretation. Data Lineage handles this complex task of effortlessly tracking all these branches and changes made in data.
Below is the diagram showing data lineage working in a simplified way.
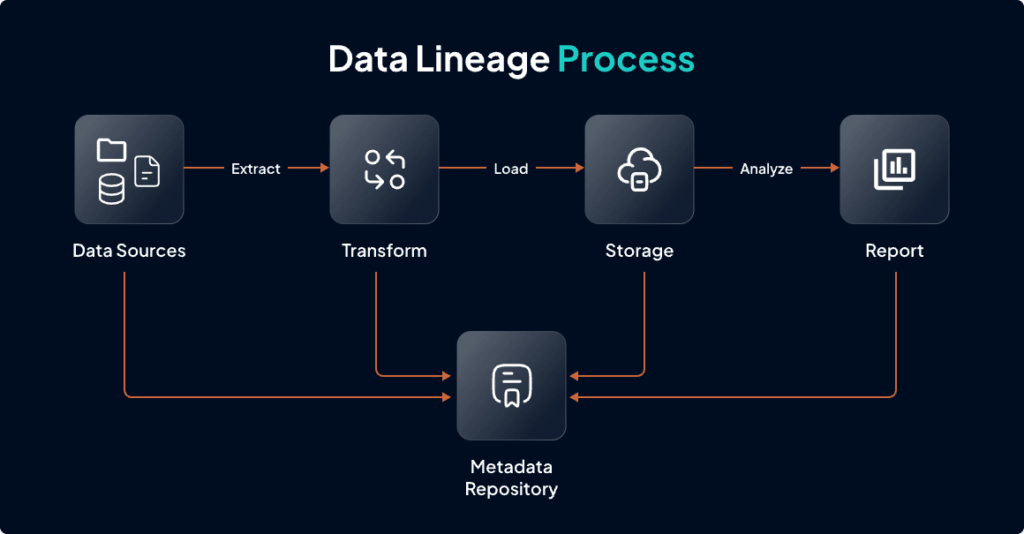
In the data lineage process, all the processes through which data has gone through are traced starting from data extraction from various data sources to its transformation and then loading to a data warehouse, up to building reports and visualization for detail analysis. In data lineage, a data map framework is created that collects metadata from each step and stores it in the metadata repository which is used for lineage analysis. In case of any error, it is easy to backtrack the root cause using these metadata.
Data Lineage Techniques
Below are the common data lineage techniques used on an organization’s datasets.
Pattern-Based Lineage
Pattern-based lineage evaluates data sets using metadata for tables, columns, and business reports. Once the metadata is gathered, it looks for patterns. For example, if two datasets have columns with the same name and similar data values, these two columns are linked together in a data lineage chart to establish a relationship.
Pattern-based lineage has the advantage of being platform-agnostic, which means it can be utilized in the same way across any database technology. The problem is that this procedure isn’t always reliable; it occasionally overlooks relationships between datasets.
Self-Contained Lineage
Self-contained lineage can be carried out in a data environment that includes storage, processing logic, and master data management (MDM) for central control of metadata. A data lake is one example of such an ecosystem, as it keeps all data throughout its existence. This type of self-contained system automatically offers lineage without the need for additional tools. As we discuss data quality and stewardship, it’s important to distinguish between metadata and master data, which play key roles in the process.
However, a self-contained lineage is unaware of everything that happens outside of its environment. The constraining environment’s constrained character restricts the insights that can be gained.
Lineage by Data Tagging
Lineage by data tagging tracks data that has been marked or tagged by a transformation engine. In this case, the process tracks the data’s tag from the start to the end of the data’s journey through the system.
This method works well if your environment has a single transformation tool that handles all data transport and you understand the utility’s tagging structure. However, like self-contained lineage, this strategy is limited by the confined nature of the confining environment. It cannot be applied to data that was not generated or processed using the tool.
Lineage by Parsing
This is the most advanced type of lineage, relying on automatic reading logic to handle data. This method reverse engineers data transformation algorithms to enable full, end-to-end tracing.
This solution is difficult to implement because it must understand all of the computer languages and tools required to change and transport the data. This may comprise extract-transform-load (ETL) logic, SQL-based solutions, Java solutions, legacy data formats, XML-based solutions, and so on.
Data Lineage Best Practices
While planning and implementing your data lineage, below are the few best practices that must be followed for effective implementation.
1. Automate Data Lineage Capture
We are in a data-driven era, but still, many organizations rely on manually capturing lineage in spreadsheets or other static documents. The manual method is unsuitable for the dynamic and agile environment, where data constantly changes. Organizations implement a step-by-step automated Data lineage to trace the route of data across your systems and extract metadata to visualize the connections, linkages, and dependencies between systems and inside the data.
2. Verification and Validation of Data Lineage Regularly
Verification and validation of end-to-end data lineage progressively is important for successful data lineage implementation. Data owner verification along with data process verification, and metadata validation are practiced.
3. Include the Metadata source in the Data Lineage.
ETL software, BI tools, relational database management systems, modeling tools, corporate applications, and custom applications all generate information about your data. This metadata is critical for understanding where your data has gone and how it has been used, from source to destination.
4. Collaboration with Data Owners and Stakeholders
Best practice for collaborative relationships with data owners and key stakeholders within the enterprise needs to be developed for successful data lineage implementation. By including all stakeholders and owners in the data lineage process, there is assurance that the captured lineage meets their requirements, issues, and expectations and handles any specific data governance challenges.
5. Consistent and Standardized Documentation
Consistent and standardized documentation is critical for successful data lineage management. Create unambiguous criteria and templates for documenting data lineage, such as naming conventions, source descriptions, and transformation procedures.
Conclusion
Data lineage is an essential component of modern data management since it ensures transparency, traceability, and responsibility across the data lifetime. Organizations that employ comprehensive data lineage procedures can improve data quality, assure compliance, and make more informed data-driven decisions. As data environments evolve, data lineage will become increasingly important, making it a must-have tool for any data-driven company.
Connect with us today to improve your data management experience and achieve more with your data.
FAQs
1. What are the two types of data lineage?
The two types of data lineage are table-level and field-level lineage(column-level lineage). As their name describes table-level lineage describes the data path between the tables, and field-level lineage describes data processing between the tables, among various fields.
2. What are the steps for data lineage?
The steps for data lineage include:
Identify all data sources
Define data elements
Map data flows
Use data lineage tools
Establish data governance policies
Monitor data lineage
Train staff on using data lineage tools
3. What is a good data lineage?
A good lineage needs to follow all best practices with accuracy and scalability. It should be well integrated with all data sources, follow all governance policies, and provide a safe and secure data pipeline. A good data lineage should be automated to capture and reduce human error risk and ensure real-time updates.
4. What is the difference between data catalog and data lineage?
Data Catalog and Data Lineage are used to manage data but for different purposes. A Data Catalog is a library of data assets which focuses on high-level structures like databases or data sources while data lineage works at a granular level and focuses on data transformation and movement through various systems.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




