

Imagine launching a dashboard and realizing your revenue metrics just vanished—again. Today, with hundreds of pipelines running at the same time, even simple schema edits and uncertain data ownership can cause significant problems. That’s when you need to start thinking about data contracts.
Table of Contents
Following the API-first strategy in software engineering, data contracts act as formal agreements among providers and users of data that keep key datasets structured, consistent, and current.
In this blog, we’ll dive deep into what data contracts are, why they matter, how they work, tools that enforce them, and how to implement them in real-world data stacks, so your pipelines are resilient, reliable, and ready for scale.
What are Data Contracts?
Data contracts are formal, machine-readable agreements between data producers and consumers that describe the structure, meaning, and standards surrounding shared data assets. Just as APIs prevent API changes from interrupting ongoing operations in software engineering, they maintain the stability of schemes, ensure fields are properly defined, and guarantee the freshness of the data. Such contracts create the base for SLAs, automated validations, and impact-aware development in current data ecosystems.
Common types include schema contracts (column-level structure), semantic contracts (meaning and constraints), and freshness contracts (timeliness and latency requirements), enabling scalable, reliable, and collaborative data workflows.
Why Data Contracts Matter?
Preventing Silent Failures
In most cases, broken schemas are not spotted until vital dashboards or pipelines are affected. By introducing structure early, data contracts show issues from rapid breaking changes during development.
Improving Data Governance and SLAs
Contracts define expectations around schema, data freshness, and delivery guarantees. Clarity in policies boosts the framework for governance and helps in following the data SLAs between the producer and consumer.
Scaling Collaboration Across Domains
Using data mesh, organizations rely on contracts to guide developers from various domains and ensure they all use the same definitions and expectations.
Enabling Trust in Self-Serve Analytics
If users know the data meets contract requirements, they feel more confident in it. As a result, people start using self-service tools more, and the teams supporting these systems face less demand.
Key Components of a Data Contract
Schema Definition
This outlines the expected structure of the dataset field names, data types, nullability rules, and primary keys. A strong schema holds together the organization’s projects and tools.
Semantic Expectations
Apart from providing the structure, contracts state the particular rules for each area. For example, a status can only be either “active” or “inactive”. They make certain that the business rules are always followed in every transaction.
Freshness & Volume SLAs
Contracts can set up how often data updates and how much information streams in (like “data should be updated every 30 minutes,” or “we need at least 1,000 rows a day”) so things work smoothly.
Ownership & Metadata
Each contract should name the data producer, the responsible team, and the notification channels for failure or schema violation, critical for governance and incident response.
Versioning & Change Management
Contracts should be built with rules for tracking changes and spreading updates, allowing previous systems to function correctly.
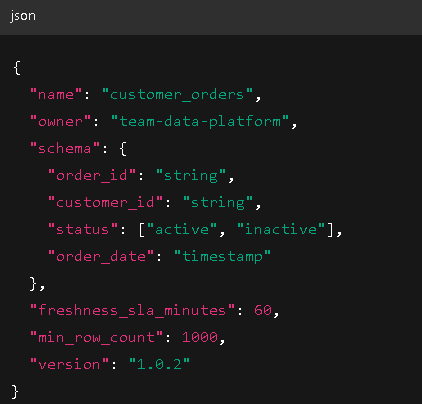
Data Contracts vs. Traditional Schema Validation
Data contracts and traditional schema validation both aim to ensure data quality, but they differ in scope and approach. Being aware that these methods differ helps organizations choose what is best for handling data.
| Feature | Traditional Validation | Data Contracts |
| Scope | Schema-only | Schema + semantics, SLAs, metadata |
| Enforcement | Manual or ad hoc | Automated via CI/CD workflows |
| Alerting & Monitoring | Rare or manual | Integrated with observability tools |
| Evolution Support | Weak schema change tracking | Strong version control & backward compatibility |
| Governance | Informal | Formal, owned contracts with audit trails |
| Ownership Clarity | Unclear or undocumented | Explicit data producer/consumer ownership |
| Business Logic Validation | Not enforced | Enforced through semantic rules |
| Testing & CI Integration | Limited | First-class support in pipelines |
| Downstream Awareness | Absent | Lineage-aware impact analysis |
How Data Contracts Improve Collaboration
Decoupled Development
Data contracts help producers and consumers communicate clearly with each other. The enforceable rules ensure producers can safely make changes, knowing old versions will still work. Consumers are confident the data won’t secretly disrupt their pipelines.
Enabling Domain Ownership
Contracts play a role in supporting ownership of data that is not centralized. By following the same agreements, each domain team can design, control, and share their data products, saving time for those in data engineering.
Promoting Accountability
With clear SLAs, information about who owns data, and a record of where it came from, data contracts help make it clear who is responsible and what happens if agreed-upon standards aren’t met.
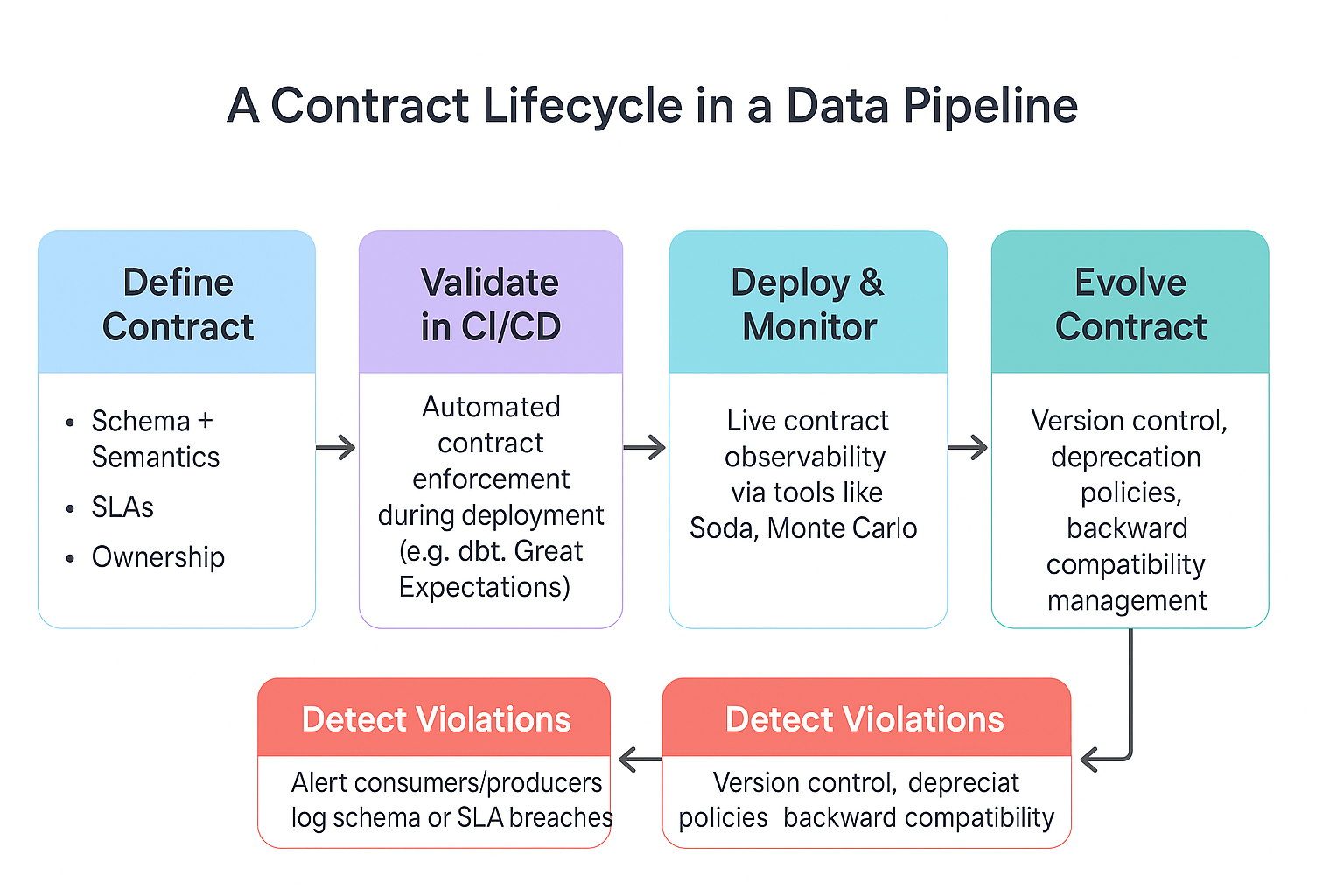
Implementing Data Contracts: Step-by-Step
Define Expectations
Begin by aligning data producers and consumers on key requirements, field structure, semantics, freshness, and delivery frequency.
Write the Contract
Formalize schema, metadata, and semantic rules using YAML or JSON. Include types, nullability, and business rules.
Enforce with Tools
Use things like dbt contracts to automatically check that the data meets the rules in your contracts.
Automate in CI/CD
Embed validations in CI/CD pipelines using GitHub Actions, GitLab CI, or CircleCI to catch schema violations before deployment.
Monitor & Alert
Use tools like observability platforms or pipelines that look out for contracts to spot when something doesn’t match (for example, when schemas change or SLAs are broken).
Manage Versions
Apply semantic versioning and changelogs to support schema evolution without breaking consumers.
Challenges and Pitfalls
Adoption Resistance
Some engineering teams may not want to use data contracts because they feel it will add complexity. Solution: Make sure CI/CD’s monitoring automates many manual aspects of the workflow.
Schema Drift vs. Model Evolution
It is difficult to tell apart intentional schema changes from breaking drift. Solution: Ensure that teams use designated versioning and changelog practices.
Tooling Maturity
The ecosystem is evolving, and not all tools offer full contract support. Solution: Start with extensible platforms like dbt or Great Expectations.
Legacy Systems
Enforcing contracts retroactively is difficult. Solution: Apply contracts incrementally, starting with critical pipelines and gradually expanding coverage.
Best Practices for Data Contracts
Start Small
Focus on gaining insights from the main datasets that are key to supporting your business. By doing this, the project highlights the benefits from the outset and gets stakeholders interested in continuing with data governance.
Co-Ownership Approach
Create data schemas, Service Level Agreements, and define the meaning of data terms after consulting with the people who produce as well as use the data.
Automate Validation
Including automated checks for contracts in your CI/CD pipelines can be done using dbt tests, Soda, or Great Expectations. Using automation, we can spot data problems early.
Communicate and Document
Keep all versions of the contract well organized and recorded. Ensure that contract breaches or any important updates are quickly reported to stakeholders so that everyone stays informed.
Tools That Support Data Contracts
- Tecton
- A real-time feature store for ML that enforces schema and freshness contracts on feature data.
- OpenMetadata
- An open-source metadata platform that makes it easy to formally describe and control how data is moved and used as it goes through different processing steps.
- Monte Carlo / Soda
- These tools monitor data quality and automatically alert stakeholders to contract violations, schema drift, or SLA breaches.
- Datafold
- Performs some simple tests to check if changes made to the database will cause problems before they get sent to the live website.
- Great Expectations
- Open-source framework that validates data quality rules and enforces expectations at runtime.
- dbt Contracts (v1.5+)
- Allows you to define schema-level constraints (e.g., data types, nullability) directly in dbt model configurations.
Real-World Use Cases
E-commerce
A schema change in the product catalog, like removing a price field, can silently break downstream recommendation models, leading to lost revenue opportunities.
Healthcare
If patients’ diagnosis codes change format, it can affect the reporting on clinical dashboards and may violate the regulations set by HIPAA.
SaaS
When the growth team tried to rename a column in the user database, this led to problems with both retention and campaign targeting, showing the importance of enforcing change governance through contracts.
Conclusion
Data contracts are more than just technical guardrails; they are foundational to building trust between data producers and consumers. By formalizing expectations around schema, semantics, and service-level agreements, contracts reduce breakages, enhance data quality, and streamline collaboration. In an age of growing data complexity, decentralized teams, and real-time decision-making, they provide the structure needed for scalable, governed, and reliable analytics ecosystems.
Whether you’re working with a big data system or just handling one data pipeline, using data contracts can help things get better. Start small: pick a high-impact dataset, define expectations, and automate enforcement. The benefits of transparency, agility, and resilience will compound as your data ecosystem matures.
Frequently Asked Questions
What is a data contract in data engineering?
A data contract helps data producers and consumers agree on the details of schema, semantics, and SLAs to guarantee smooth and proper sharing of data.
How are data contracts different from schemas?
Schemas define data structure only. Data contracts additionally manage business rules, timeliness, ownership details, and version tracking, helping teams cooperate more effectively.
Can I use data contracts with dbt?
Yes, dbt supports basic data contracts through schema constraints, tests, and metadata enforcement via model.config starting from v1.5+, making it ideal for contract-driven ELT workflows.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link
