

In today’s digital era of large amounts of complex and multidimensional data, traditional databases cannot store, extract useful information, or handle data effectively. Vector database is an innovative technical advancement that can easily handle complex and multidimensional data, as required for real-time machine learning applications.
Table of Contents
What Is a Vector Database?
A vector database is a type of database that stores data in a three-dimensional space known as a vector space. Each data point is stored as a vector representing different features and properties of data. They can perform high-speed computations with complex, unstructured data types (like images, audio, text, etc.) for machine learning algorithms that involve similarity searches and computations.
For handling large volumes of complex data that require scalability, speed, and real-time processing, a vector database is a better choice than a traditional database.
Every object/data item like text, video, audio, document, or any other data, corresponds to a vector. These vectors are likely to be lengthy and complex, expressing the location of each object along hundreds of dimensions. It works based on similarity search as in similar data items end up clustered together in the database if vectorized correctly.
Let’s understand vectors in detail.
What Is a Vector?
Machine learning algorithms work on the concept of linear algebra which is why every data is converted into a vector which is easily understood by machines. A vector is an array or list of numbers containing multiple scalars of the same data type and algebraic operations can be performed on it. It can be represented as:
v = (a1,a2,a3)
A vector can be thought of as a point in n-dimensional space, where n is the number of dimensions. The above vector ‘v’ is a vector of 3 elements and could be represented as a point in 3-dimensional space.
What Is the Difference Between a Traditional Database and a Vector Database?
| Aspect | Traditional Database | Vector Database |
| Data Structure | Stores data in tables | Stores data in vector/arrays |
| Data Model | Relational model in a tabular form | Vector base model in a three-dimensional space |
| Schema | Rigid Schema | Flexible Schema |
| Query Language | Structured Query Language (SQL) | No query language, use API calls for querying |
| Search Type | Similarity search based on similarity or vector distance | Exact match search or predefined criteria |
| Indexing | Vector-specific indexing methods like HSNW or IVF to retrieve similar vectors quickly | Use indexing methods like B-tree or hash indexes to retrieve data quickly |
| Performance and Scalability | Limited performance due to vertical scalability | Improved performance due to horizontal scalability |
| Use Cases | Ideal for Machine Learning and AI applications like Recommendation engines, NLP, Large-Language Models, Real-time personalization, etc. | It is ideal for traditional business applications like record keeping, transaction management, E-commerce platforms, inventory management, etc. |
How Do Vector Databases Work?
A vector database works on the concept of semantic search which means not searching the exact keyword matching but understanding the intent of a user query and using the context to perform the search. A semantic search returns a customizable list of vectors with the smallest distance (“most similar”) keyword from the query vector. Internally, it uses word embedding or vector embedding, which is a numerical representation of text called vectors with some dimensions.
What Is Vector Embedding?
Each text or keyword has some features and properties, and based on that, these vector embeddings are created. For example, the vector embedding of apple fruit is different from that of the Apple company.
Example:
“Apple” as fruit:
[0.8, 0.2, 0.5, 0.1, 0.7] (High values on dimensions related to color, sweetness, and fruit characteristics)
“Apple” as a company:
[0.3, 0.9, 0.1, 0.6, 0.2] (High values on dimensions related to technology, innovation, revenue, and consumer electronics)
The cosine distance calculated between word vector embeddings defines how close the words are. The less the cosine distance, the more similar the words are. For example, the cosine distance between an apple(fruit) and a banana(fruits) will be less compared to the cosine distance between a banana and an apple (company).
There are various word embedding models available that are widely used, such as word2vec, Glove, BERT, GPT, fastText, and ELMo.
Vector Database Search Mechanism
There are billions of data and vectors stored in databases. So, linear search is very time-consuming and computationally expensive. So, it works on the concept of vector database indexing, which doesn’t iterate over every vector embedding in the database.
Various indexing techniques such as Locality Sensitive Hashing(LSH), KD-trees, Hierarchical Navigable Small World graphs (HNSW), Inverted File Index (IVF), or Inverted Multi-Index (IMI), are available to organize vectors in a database for semantic search.

The query goes through three main stages:
1. Indexing
The indexing techniques organize or cluster similar embedding so that the search space can be significantly reduced during queries.
2. Querying
During a query, these databases determine the region of the vector space where similar vectors are most likely to exist and search just inside that region.
3. Post-Processing
The search query result will be post-processed to produce the query’s final output. In addition, some reindexing of vectors in the database is done if needed.
This method significantly reduces the computing time and computation resources necessary to extract similar vectors, making them highly efficient for similarity search applications.
Locality Sensitive Hashing
Locality sensitive hashing is one of the database indexing functions based on the hashing technique that creates buckets of similar-looking embeddings. Then, for the search query, it goes through the same hashing function to look for similar embedding buckets.
Once it finds the matching bucket, a linear search happens only with embedding in the matched bucket, not with other buckets, which saves lots of time and computation. Then, post-processing steps are taken to return the final results.
See, the below diagram shows the internal working of the database.
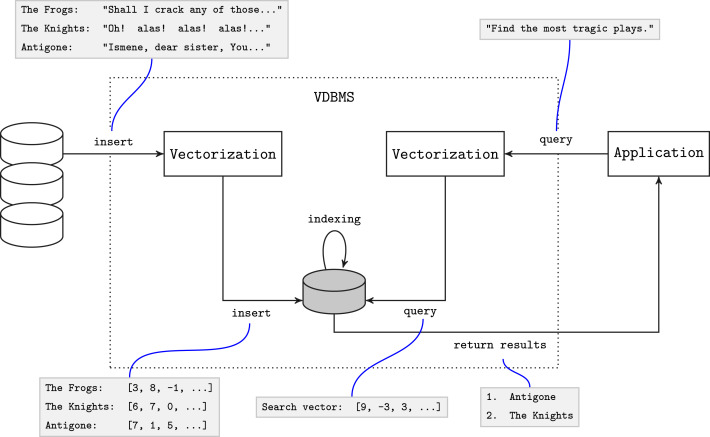
In the absence of a vector database, you would have to submit the whole dataset along with your query every time. This is simply not practical because models have input size restrictions and are also inefficient, as it would require significant resources and time. Thus, they are such an appealing choice in high-scale machine learning applications.
How Are Vector Databases Used?
They are widely used in various machine learning and Artificial intelligence applications. Because of its quick semantic search property, it is highly suitable for advanced and real-time machine learning implementations. Let’s see some use cases in the machine learning field.
1. Natural Language Processing (NLP)
The vector database and its semantic search are highly used in natural language processing to search for similar words, phrases, or documents. It converts text data into vectors using word embeddings, and all the NLP tasks like question answer, search for similarity, text prediction, etc., can be done easily,
2. Image Search
They play a key role in image recognition, where images are converted into high-dimensional vectors using Convolution Neural Networks(CNNs). This technology is used to identify images or search for similar images in a database. The face recognition system implements this technology.
3. Recommendation Systems
E-commerce websites use them widely for their recommendation systems. In the recommendation system, algorithms suggest items to users similar to their past purchase or interest history.
4. Fraud Detection
They can be used for security and fraud detection when the purpose is to identify anomalous patterns in data. Businesses can swiftly identify possible dangers or fraudulent actions by modeling typical and aberrant activity as vectors and doing similarity searches.
5. Personalized Marketing
Personalized marketing is a key differentiation for businesses these days. Businesses use them to profile clients based on their interactions and behavior and then offer them personalized services and goods.
What Are the Advantages of Using a Vector Database?
They are widely used in machine learning and AI applications, and it shows tremendous benefits to the applications:
1. Speed and Performance
It enables quick searches as it works on vector indexing and semantic search approaches. The vector indexing method searches at a faster speed for required results across large datasets with millions of data points to help optimize performance.
2. Scalability
They can scale horizontally to store and manage high-dimensional, complex, and unstructured data. They can easily expand storage and computing capacity, which is beneficial for the exponential growth of applications.
3. High Operational Efficiency
They compactly store high-dimensional arrays, thus reducing storage footprints. It also accelerates the data retrieval process, resulting in a highly efficient storage and retrieval database and a better user experience.
4. High-Dimensional Data Management
They typically provide built-in features to easily update and insert new unstructured data.
5. Adaptability and Flexibility
They are highly adaptable to diverse, dynamic, varied, and evolving data types and structures. They handle complex multidimensional data like text, images, and video effortlessly, making them super flexible.
6. Cost Efficient
They require specific expertise and abilities for installation and maintenance, thereby raising initial expenses. However, their efficiency in dealing with high-dimensional data can result in long-term savings, making them cost-efficient in the long run. Also, the horizontal scalability offered by them is more cost-effective than the vertical scalability of traditional databases.
Challenges in Using Vector Databases
They offer many advantages but have some challenges as well when using them.
1. Data Structure
They are primarily designed to handle high-dimensional vector data. They are not appropriate for data structures that do not fit well into a vector format, such as data having a large number of category variables.
2. Problematic Updates and Deletions
It works on the concept of indexing. So, modifying or deleting data in vector databases requires maintaining index consistency, which can be very challenging sometimes.
3. Computationally Expensive
Semantic or similarity searches with them can be computationally expensive, and require large computer resources, thus raising expenses potentially.
4. Latency
They may have higher latency than conventional databases, especially when working with huge datasets or complex queries.
5. High Dimensionality
As it works with high-dimensional data, sometimes it is challenging to visualize, interpret, debug, or fine-tune such high dimensions of data.
Features of a Good Vector Database
It is important to pick the right vector database that meets your organization’s requirements and helps you achieve data management goals.
1. Scalable
Check for the scalability of it in terms of the data it can manage and the number of dimensions it can accommodate. It should be scalable to millions of high-dimensional data.
2. High-Performance Metrics
A good vector database must have high performance in terms of less retrieval and storage time, efficient semantic search, and should meet your workload requirements.
3. Indexing Methods
Indexing methods supported by vector databases should be in terms of a flexible schema design. Indexing mechanisms are crucial to ensure efficient similarity search and retrieval operations.
4. Easy Integration
Check its compatibility with your current systems, tools, and programming languages. Ensure that they support various APIs, connectors, or SDKs for integration with the existing system.
5. Easy Usability
The vector database’s ease of setup, configuration, and maintenance are important features. A user-friendly design and adequate documentation may both increase and decrease learning curves.
What Are the Top Vector Databases?
1. Chroma
Chroma is an open-source embedding database that simplifies the development of LLM apps by making knowledge, facts, and skills pluggable. With Chroma, it is easy to manage text documents, convert text to embeddings, and do semantic searches.
2. Pinecone
Pinecone is a managed vector database service that is equipped with cutting-edge indexing and search capabilities that can tackle high-dimensional data with scalability and flexibility. It’s designed for real-time large-scale machine learning applications that effectively analyze high-dimensional data without compromising performance or accuracy.
3. Milvus
Milvus is an open-source vector database designed for scalable and reliable AI and analytics workloads. It has a distributed architecture that enables Milvus to handle billions of vectors. It enables similarity search at scale and querying massive embedding vectors generated by recommendation systems, making it suitable for deep learning systems.
4. Weaviate
Weaviate is an open-source vector database with a GraphQL API. It allows you to store data objects and vector embeddings from your favorite ML models and enables users to run similarity searches using a simple query language. It can scale easily to billions of data points and seamlessly integrates with platforms like OpenAI, Cohere, HuggingFace, and others.
5. Faiss
Faiss is an open-source library created by Meta for the clustering of dense vectors and the swift search for similarities. It has algorithms capable of searching through vector sets of varied sizes, including some that may exceed RAM capacity. It supports Python/NumPy integration completely.
Conclusion
Vector databases are great tools for managing and storing complex, unstructured, and high-dimensional data. They excel at providing accurate and rapid similarity search capabilities, allowing for effective retrieval of relevant information. They are adaptable and flexible enough to handle various types of data, such as text, images, audio, and video. They can also provide scalability, which means they can manage big datasets while maintaining high performance and operational efficiency.
However, sometimes we face challenges with them due to their high dimensionality and latency issues. Managing and maintaining them can be difficult, and they may not provide the same level of comprehensive data management as more established databases. But, still they are widely used in high-performing, complex machine-learning algorithms, and AI applications. Many big companies are using them nowadays.
To seamlessly integrate and transform your data for AI and analytics, Hevo provides an efficient, no-code data pipeline solution. Sign up for a 14-day free trial today!
FAQs
Q1: What is the difference between SQL and vector databases?
Vector databases use specialized indexes, optimized for storing and retrieving for managing high-dimensional vector data. They are designed around the concept of indexing and semantic/similarity search in a high-dimensional space.
In contrast, SQL organized data in tables as rows and columns which is optimized for the storage and retrieval of structured data. Queries in SQL involve operations such as joins, filters, and aggregations based on exact matches or range criteria.
Q2: What are four examples of vectors?
Four examples of vectors used in AI are: word embeddings (text vectors), image embeddings (visual vectors), sentence embeddings (textual context vectors), and audio embeddings (sound feature vectors)
Q3: Does ChatGPT use a vector database?
ChatGPT does not inherently use an in-built database. However, the performance of ChatGPT can be enhanced by integrating it with vector databases.
Q4: Can SQL be used as a vector database?
SQL Server has built-in support for vectors using the vector data type.
Q5: What are the three main data types under vector?
The three basic data types are points, lines, and polygons. Points contain individual x and y locations. Lines are composed of two vertices/points that are connected. Polygons are composed of 3 or more vertices/points that are connected and closed.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





