

A data lake is designed to store vast amounts of raw data, but without proper governance, it can turn into a data swamp—disorganized, unreliable, and difficult to analyze. Businesses ingest data from multiple sources, including IoT devices, logs, and social media, yet without a structured approach, finding meaningful insights becomes a challenge. In this blog, we’ll explore the key differences between a data lake vs data swamp, the risks of poor data management, and how modern solutions like data governance frameworks and the data lakehouse model help maintain data integrity and usability for analytics.
Table of Contents
What is a Data Lake?
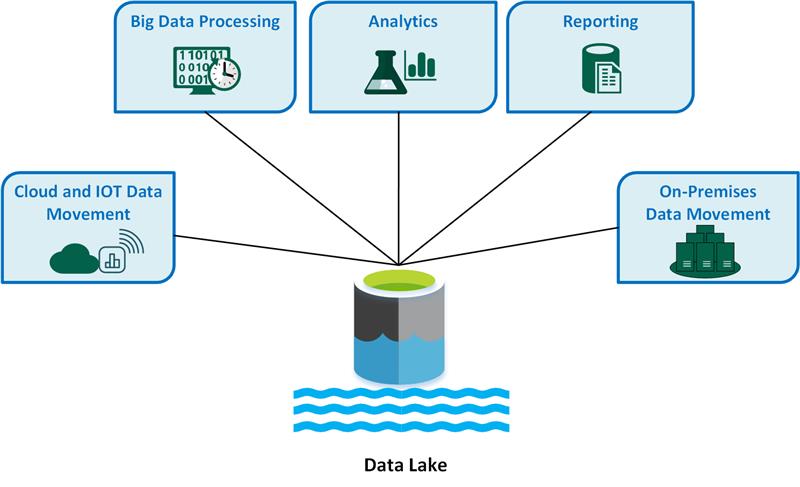
A data lake is a scalable, cost-effective storage repository that stores raw data from multiple sources in structured (CSV, Excel), semi-structured (JSON/XML), and unstructured formats (IoT Devices, audio/video format)—without requiring predefined schemas. Cloud-based examples include AWS S3 and Azure Data Lake Storage (ADLS).
Organizations commonly use data lakes for backups and archiving old or infrequently accessed data. Additionally, data lakes serve as repositories for incoming data, including data without an immediately defined purpose. The data remains in the lake until stakeholders determine its value, after which it can be processed and leveraged for various analytical needs.
Key Features of Data Lake
- Low-Cost Storage: Provides a cost-effective storage solution compared to data warehouses; uses object storage solutions like AWS S3, Azure Data Lake Storage, or Google Cloud Storage.
- Schema on Read: Unlike traditional databases (schema-on-write), data lakes allow users to define schema during analysis.
- Data Ingestion & Integration: Supports batch, real-time, and streaming data ingestion. Integrates with various ETL tools, databases, and big data platforms.
- Metadata Management & Data Cataloging: Uses metadata tagging for better data discovery and implements data catalogs to organize and search data efficiently.
What is a Data Swamp?
The term “Data Swamp” emerged recently to describe the challenges of poorly managed data lakes, where low-quality or inaccurate data fails to maintain ACID principles. It results from weak data governance and quality controls, leading to inconsistencies and restricted accessibility for data engineers and scientists. A lack of metadata management further complicates data discovery and analysis. Even hybrid models, combining data warehouses and data lakes, can degrade into a data swamp if mismanaged.
Consequences of a Data Swamp
- Unusable Data – Filled with inaccurate, outdated, or redundant data, a data swamp leads to unreliable insights and poor decision-making.
- Loss of User Trust – Inconsistent, inaccessible, or unreliable data erodes confidence, discouraging users from relying on it for analytics and reporting.
- Wasted Resources – Storing irrelevant or duplicate data inflates storage costs and strains computational resources without adding value.
- Poor Scalability – As a data swamp expands, inefficiencies worsen, causing slower queries, excessive storage consumption, and degraded performance.
Data Lake vs Data Swamp: What’s the Difference?
| Characteristics | Data lake | Data swamp |
| Data quality | High-quality data is validated and curated before or during storage. | Poor data validation and cleansing processes create low-quality, inconsistent data swamps. |
| Data Discoverability | Rich metadata exists to help with data discovery. | Insufficient or missing metadata makes data discovery hard. |
| Data governance | A proper data governance framework is in place. | Inadequate or absent data governance policies and procedures result in unchecked data accumulation and proliferation. |
| Data Lineage | It is easy to track the data – its history and lineage. | There is no clear data lineage, as no one is keeping track of historical, archived data. |
| Security and Compliance | Strong security measures and compliance controls. | Lacks security and compliance measures lead to risks. |
| Data Maintenance | Data is actively maintained for consistency and usability by cleaning and pruning outdated datasets. | Due to lack of data maintenance, users have to spend a lot of time on data discovery and cleaning and are left with outdated, irrelevant data. |
| Data integration | Data can be integrated effectively for analytics. | Difficulty in integrating data for analytics due to poor organization. |
Data Lake vs. Data Swamp: A Detailed Comparison
1. Data Quality
- Data Lake: Maintains high-quality data by enforcing governance guidelines, structuring raw data for accessibility, and pruning irrelevant data before ETL processing.
- Data Swamp: Lacks proper validation and cleansing, leading to inaccuracies, inconsistencies, and duplicate data that undermine trust and analytics.
2. Data Discoverability
- Data Lake: Rich metadata, guided by data lineage and governance principles, enables efficient data discovery.
- Data Swamp: Poor metadata management and documentation make it difficult for engineers to locate relevant data.
3. Data Governance
- Data Lake: Implements governance policies to ensure data quality, security, and accessibility. Includes guidelines for formats, models, metadata, and master data management (MDM).
- Data Swamp: Lacks governance structures, leading to poor data visibility, inaccurate insights, and unreliable performance metrics.
4. Data Lineage
- Data Lake: Uses metadata to track data lineage, enabling traceability of transformations across ETL processes and identifying errors at the source.
- Data Swamp: Missing or incomplete metadata results in no lineage tracking, making it impossible to detect inconsistencies and errors.
5. Security & Compliance
- Data Lake: Implements security measures like role-based access control, encryption, and audit logs, ensuring compliance with regulations like GDPR and HIPAA.
- Data Swamp: Lacks proper access controls, increasing risks of data breaches, compliance violations, and unauthorized access.
6. Performance & Maintenance
- Data Lake: Uses structured governance, security protocols, and automated retention policies to optimize performance and storage efficiency.
- Data Swamp: Poor governance leads to redundant, outdated, and unstructured data, causing slow queries, high storage costs, and system inefficiencies.
7. Data Integration
- Data Lake: Supports seamless ETL processes, enabling smooth integration with data warehouses (e.g., Snowflake) and BI tools (e.g., Power BI) for efficient querying and analysis.
- Data Swamp: Inconsistent, unstructured data complicates ETL, making integration with data warehouses and analytics tools complex and labor-intensive.
How a Data Lake Turns Into a Data Swamp
- Lack of Data Governance
Without well-defined metadata and governance policies, tracking data lineage becomes difficult. This lack of accountability leads to poor data quality, security gaps, and reduced usability for analytics. - Limited Data Discoverability & Accessibility
Without a structured data catalog, users struggle to locate relevant datasets. The absence of indexing and tagging forces manual searches, making data retrieval inefficient. - Poor Data Quality Management
A lack of validation, standardization, and cleansing processes results in a bloated data lake filled with low-quality, unstructured data, undermining analytics and decision-making. - Lack of Monitoring & Maintenance
Without regular cleaning and monitoring, outdated and irrelevant datasets accumulate, degrading system performance and making data retrieval cumbersome. - Mismanagement of Data Lakes
Dumping raw data without clear objectives or documentation turns a data lake into a chaotic repository, leading to storage inefficiencies and unusable data.
Real-World Scenario: Lack of Data Catalog and Mismanagement in Healthcare Data Lakes
A major hospital network deployed a data lake to centralize electronic health records (EHRs), patient histories, and physician notes across multiple departments and clinics. The goal was to enhance patient care and enable predictive analytics for early disease detection.
However, due to the absence of a data catalog and proper governance, the data lake quickly deteriorated into a data swamp. Data scientists spent more time manually cleaning inconsistent and duplicate data rather than deriving insights. Inconsistent data formats across hospital branches further complicated integration, preventing a unified view of patient records and increasing the risk of misdiagnoses and treatment delays.
Additionally, poor data governance resulted in personally identifiable information (PII) being mixed with general medical data, leading to HIPAA compliance risks and potential legal repercussions. Without structured management, the hospital’s data lake became an unmanageable, inefficient, and costly data swamp—hindering patient care, slowing medical research, and exposing the organization to regulatory risks.
Best Practices to Prevent the Formation of a Data Swamp
- Robust Governance & Active Management: Establish clear ownership, access controls, and accountability to ensure data integrity and compliance. Assigning roles like CDO and data stewards safeguards data quality and security.
- Centralized Data Catalog & Metadata Management: A data catalog improves visibility, governance, and discoverability, while metadata tagging ensures structured, accessible datasets, reducing redundancy and confusion.
- Enforce Data Quality Monitoring: Organizations must implement automated data validation checks to detect inconsistencies, missing values, and anomalies, preventing errors from propagating through the system.
- Strengthen Access Controls & Security Measures: Implement user authentication, encryption, and role-based access control (RBAC) to manage permissions effectively. These measures ensure that only authorized users can access or modify critical records, safeguarding data privacy and regulatory compliance (e.g., GDPR, HIPAA).
- Adopt Data Lifecycle Management: Define clear data lifecycle policies and procedures to govern data ingestion and streamline processes, ensure that outdated or irrelevant data is periodically cleaned or archived, optimal resource utilization, and cost efficiency.
- Invest in Data Cataloging Tools: Leverage advanced data cataloging tools and platforms to automate metadata management, data lineage tracking, and data discovery processes.
How do Data Lakehouses Prevent Data Swamps?
A data lakehouse is a hybrid data architecture that combines the scalability and flexibility of a data lake with the structured governance and reliability of a data warehouse. It merges the cost-efficient storage of data lakes with the structured querying and transactional capabilities of data warehouses, enabling organizations to store, manage, and analyze big data efficiently while reducing data quality issues.
One of the most well-known implementations of a data lakehouse is Databricks Delta Lake. Here’s how it helps prevent data swamps:
- Built-in Governance & Schema Enforcement: Automatically validates schema during data ingestion, preventing duplicate, corrupt, or misformatted data.
- Unified Storage & Metadata Management: Centralized metadata management ensures data consistency, supports transactions, and enables versioning with tools like Apache Iceberg and Delta Lake.
- Optimized Query Performance & Reduced ETL Overhead: Supports SQL-based queries on raw data, reducing ETL workloads and improving integration with BI tools and machine learning workflows.
Conclusion
A well-managed data lake provides a scalable and flexible repository for enterprise data. Still, without proper governance, metadata management, and data quality controls, it can quickly degrade into a data swamp—making data unsearchable, unreliable, and unusable. Organizations must implement structured governance policies, data catalogs, schema enforcement, lifecycle management, and security measures to prevent this.
Adopting modern solutions like the data lakehouse—which blends the flexibility of data lakes with the structured governance of data warehouses—can help organizations mitigate risks associated with poor data management while optimizing performance and usability. By proactively managing data lakes and leveraging emerging technologies, organizations can ensure their data remains a strategic asset rather than an operational burden, driving innovation, efficiency, and informed decision-making.
FAQs
1. What is a data swamp?
A data swamp is a mismanaged data lake filled with disorganized, low-quality, and unsearchable data, making it inaccessible and unusable for analytics and decision-making.
2. How to prevent a data lake from becoming a data swamp?
Implement governance, metadata management, schema enforcement, data catalogs, quality monitoring, and lifecycle policies to maintain structured, accessible, and high-quality data.
3. What is the difference between a data lake and a data lakehouse?
A data lake stores raw, unstructured data, while a data lakehouse integrates governance, schema enforcement, and ACID transactions, improving data integrity, performance, and analytics capabilities.
4. What is the difference between a data pond and a data lake?
A data pond is a smaller, purpose-driven subset of a data lake, containing specific, well-organized datasets for targeted analytics, whereas a data lake holds vast, diverse datasets.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




