

Data-driven enterprises face overwhelming challenges because they handle enormous amounts of structured and unstructured data. Modern business success depends on proper data management because it drives insightful operations, helps executive decisions, and preserves market leadership. Selecting the appropriate data architecture between data fabric and data lake remains complicated for organizations.
Table of Contents
The blog provides cornerstone information about data fabric vs data lake, including its main advantages and when organizations should use each. This article will provide your organization with a necessary plan to choose the optimal data solution that matches its individual requirements.
What is Data Fabric?
The data management architecture of data fabric unites and interoperates multiple data storage types from both hybrid cloud and multi-cloud and on-premise locations. Data fabric ensures that the data is well-connected, available, and, lastly, administered in real-time, which helps the organizations to make decisions faster.
Key Components of Data Fabric:
- Data Integration: It combines all data sources, including cloud-based systems as well as on-site databases, IoT devices, and third-party applications, into a single integrated system.
- Metadata Management: AI and machine learning automatically detect and categorize information and maintain records across the company.
- Data Virtualization: It allows real-time data access to distributed data resources through its virtualization approach.
- Security & Governance: The system implements full-scale security and governance measures that apply protections, compliance frameworks, and privacy mechanisms to all its connected databases.
- Self-Service Data Access: Data fabric provides users access to self-service data features that allow data scientists and business analysts to get and analyze business information independently without IT team dependencies.
What is Data Lake?
A data lake is a centralized repository that stores large volumes of raw, unstructured, semi-structured, and structured data in its native format. It enables organizations to collect and retain data from multiple sources without needing immediate processing or transformation. This flexibility makes data lakes highly scalable and cost-effective for machine learning, big data analytics, and concurrent data exploration.
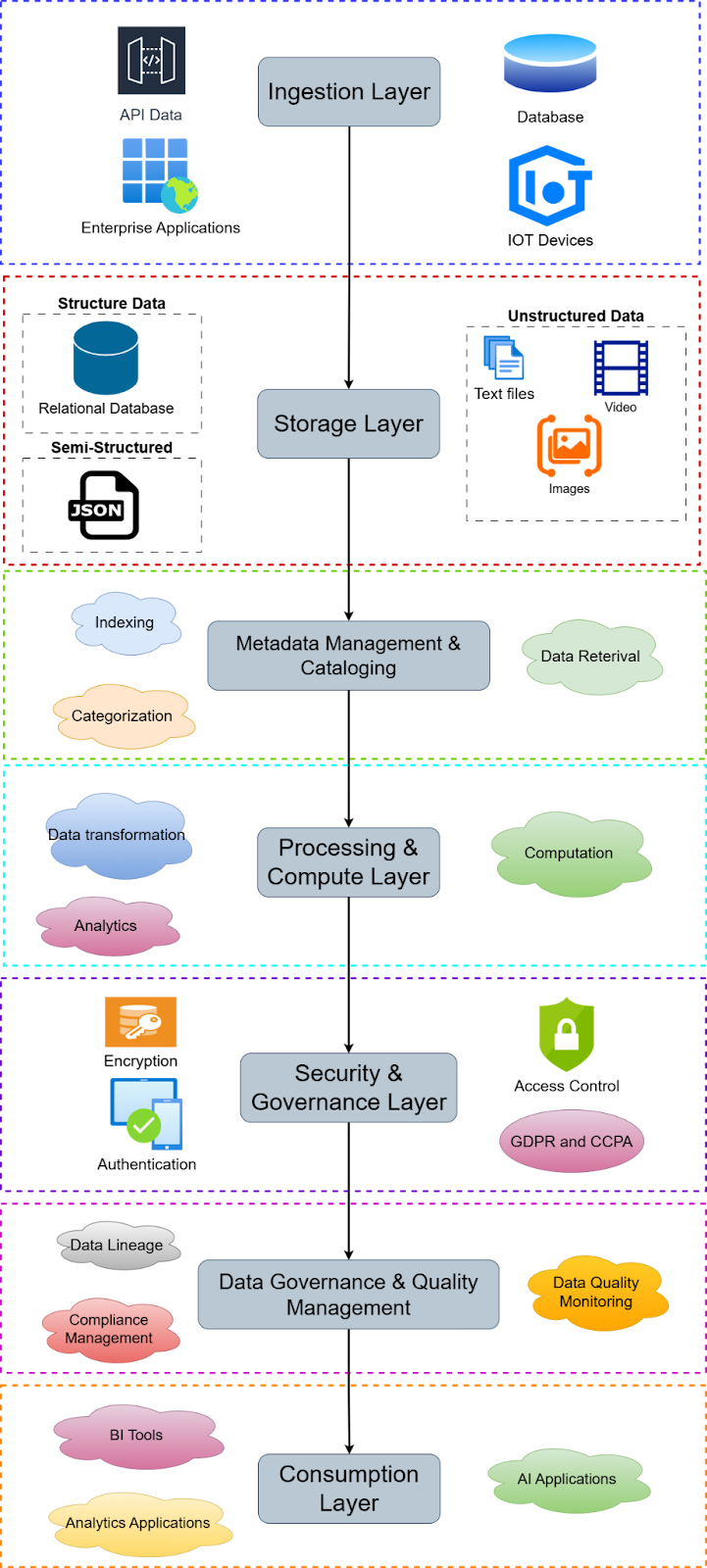
What are the core components of a Data Lake?
A Data Lake consists of several essential modules enabling efficient storage, processing, and management of massive datasets. Here are the key components:
- Ingestion Layer: The ingestion layer collects and loads data from multiple sources, including databases, IoT devices, streaming data, APIs, and enterprise applications.
- Storage Layer: This layer provides scalable, cost-efficient storage for structured, semi-structured, and unstructured data.
- Metadata Management & Cataloging: Data Lakes require a metadata layer to index, categorize,e and enable easy retrieval of stored data.
- Processing & Compute Layer: This component enables data transformation, analytics, and computation.
- Security & Governance Layer: This layer controls access, encryption, authentication, and compliance with regulations like GDPR and CCPA.
- Consumption Layer: The consumption layer provides interfaces for business intelligence (BI), analytics, and AI applications to access and utilize data.
- Data Governance & Quality Management: This component helps eliminate data silos, prevent duplication, and improve trust in data by providing automated validation and standardization mechanisms.
What are The Similarities Between Data Fabric and Data Lake?
Data fabric and data lake exist for separate needs but show parallel characteristics regarding data management systems along with scalability aspects and analytical abilities are given below:
- These data systems enable large-scale data management from multiple sources through their ability to process structured and semi-structured data variants.
- Both architectures are cloud-agnostic due to their ability to work in on-premises and cloud and hybrid computing systems.
- They allow users to run advanced analytics and AI/ML applications through their ability to process large datasets.
- Scalability and cost efficiency stand out as common benefits of these two architectures, enabling them to handle increasing data requirements.
- These solutions provide governance and security features, including RBAC access control with encryption capabilities, data masking methods, and GDPR and CCPA compliance features.
- Real-time and batch-processing methods exist in these two architectures to meet the diverse requirements of business operations.
Key Differences Between Data Fabric and Data Lake
| Feature | Data Fabric | Data Lake |
| Definition | Integrates and governs data across multiple sources. | Centralized repository for storing raw data. |
| Primary Purpose | Enables real-time access and governance. | Provides scalable storage for analytics and AI. |
| Data Processing | Virtualizes and connects data from multiple sources. | Follows a schema-on-read approach, processing data later. |
| Storage Strategy | Does not store data but orchestrates and unifies it. | Stores massive raw datasets from various sources. |
| Governance & Security | Built-in compliance and governance automation. | Requires additional governance and security layers. |
| Use Cases | Best for real-time analytics, governance, and compliance. | Ideal for big data storage, AI/ML training, and deep analysis. |
| Performance & Latency | Provides low-latency, real-time data access with AI-driven optimizations. | May suffer from data retrieval delays. |
Data Fabric vs Data Lake: Detailed differences
- Data Processing Model
- Data fabric follows a metadata-driven and AI-enhanced approach, where data is accessed in real time without requiring physical duplication.
- Data lake follows a schema-on-read approach, meaning data is stored in its raw format and processed only when needed.
- Data Storage Strategy
- Data fabric is an orchestrator that allows organizations to access and govern data across multiple platforms without creating additional copies.
- Data lake physically stores all ingested data in low-cost storage systems such as Hadoop and Azure data lake storage, making it ideal for big data applications.
- Governance and Security
- The built-in governance features of Data Fabric including automated data cataloging and compliance enforcement (GDPR, CCPA) ensure data integrity and regulatory compliance across multiple environments.
- Data lake requires additional governance mechanisms as it inherently lacks structured data management.
- Scalability and Performance
- Data fabric can integrate multiple data environments without requiring additional storage infrastructure making it suitable for real-time data access and AI-driven analytics.
- Data lake scales by adding storage capacity allowing organizations to store petabytes of raw data. However, querying large amounts of unstructured data can cause performance bottlenecks.
- Cost Implications
- Data fabric may have higher initial implementation costs requiring AI-driven metadata management, data virtualization, and governance automation. However, it reduces long-term storage costs by eliminating data redundancy.
- Data lake is cost-effective for storing large volumes of data but organizations may face hidden governance, security and performance optimization costs.
How to Choose Between Data Fabric and Data Lake?
Below is a questionnaire designed to guide you through this decision-making process.
- Do you need to integrate data from multiple disparate sources into a unified view?
- Yes: Consider data fabric, which incorporates and provides seamless access to diverse data sources.
- No: A data lake might suffice for centralized storage if integration is not a primary concern.
- Does your organization require real-time data processing and analytics?
- Yes: Data fabric supports real-time data access and processing making it suitable for immediate analytics needs.
- No: For batch processing and historical data analysis a data lake is appropriate.
- Do you need a centralized repository to store large volumes of raw data for future analysis?
- Yes: A data lake provides scalable storage for vast amounts of raw data.
- No: If centralized storage isn’t necessary, data fabric can connect existing data sources without duplicating data.
- Is your organization prepared to manage the scalability and performance of large-scale data?
- Yes: Data lake architectures are designed for scalable storage but require management of performance optimization.
- No: Data fabric offers scalability in data integration without the need for extensive storage management.
- Are your analytical needs focused on historical data, machine learning or big data analytics?
- Yes: Data lake is well-suited for these purposes, providing a repository for large datasets used in advanced analytics.
- No: Data fabric is more appropriate for operational analytics and real-time insights.
- Does your current infrastructure include multiple data that need to be connected?
- Yes: Data fabric is designed to integrate and manage data across diverse environments.
- No: A Data lake might be sufficient if your environment is more homogeneous.
Use Cases of Data Fabric and Data Lake
Data Fabric Use Cases
1. Fraud Detection in Financial Services: Financial institutions use data fabric to combine transaction data with customer profiles and outside database information, thus enabling them to identify fraudulent activities instantly.
2. Customer Sentiment Analysis in Retail: The analysis of retail customer sentiment exists through data fabric. Companies evaluate public social media and review content to find their most appealing products alongside trending market items.
3. Predictive Maintenance in Manufacturing: The implementation of data fabric enables manufacturing companies to unite information collected from machine sensors as well as performance records together with other equipment information. The combined system enables predictive maintenance since it uses pattern recognition to help businesses anticipate their equipment breakdowns.
Data Lake Use Cases
1. Advanced Analytics and Machine Learning in Finance: Financial institutions can store vast amounts of raw data in data lakes, enabling advanced analytics and machine learning applications. For instance, banks can develop predictive models to forecast market trends and personalize customer services.
2. IoT Data Management in Manufacturing: The management capabilities of data lakes in the manufacturing industry allow companies to process IoT device data. Organizations leverage raw sensor data storage to perform real-time operations and optimize their manufacturing processes while making possible predictive maintenance.
Conclusion
In today’s eras of data management, data lakes are centralized data repositories that store extensive raw data in their natural format, making them ideal for machine learning and big data analysis. On the other hand, data fabrics provide an integrated architecture for seamless access, governance, and real-time data processing across different platforms, ensuring its security and consistency. Picking between the two depends on data integration requirements, processing needs, authority rules, and business objectives. Sometimes, we choose a hybrid model that has features of both for comprehensive solutions and to combine their strengths. To improve your data replication process, sign up for a 14-day free trial and experience the ease of automation with Hevo.
FAQs
1. What is a data fabric?
A data fabric is an integrated architecture that enables seamless access, governance, and real-time data processing across diverse environments, ensuring data consistency and quality.
2. Is Microsoft Fabric a data lake?
No, Microsoft fabric is not solely a data lake; it is an end-to-end, cloud-based SaaS platform for data and analytics that integrates various tools including data factory, Synapse analytics, and Power BI, built upon a unified lake house architecture called OneLake.
3. What is the difference between Data Mesh and Lakehouse?
A data mesh is a decentralized data architecture that assigns data ownership to individual domains, promoting domain-oriented data management. In contrast, a lake house is a centralized architecture combining data lakes’ flexibility and scalability with data management and ACID.
4. What is the difference between data fabric and data lake?
Data fabric is an architectural method that enables continuous data integration, governance, and management across different environments and also provides a real-time and consolidated view of data from other sources. A data lake is a centralized repo that stores a large amount of raw data in its original format while maintaining its structure, semi-structured and unstructured data for later analysis.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





