

With today’s enormous data, it is nearly impossible for engineers to build an application without a clear roadmap of data functions and its organization. Data modeling provides a blueprint with simplified diagrams, symbols, and text to efficiently represent how data flows and interacts. This simplifies the job of engineers in designing the data architecture for software applications.
Table of Contents
In this article, we will explore different types of data modeling and how you can create one for your use case.
What is Data Modeling?
Data modeling is a visual representation of how data is collected and managed within an organization. It represents associations, hierarchies, structures, and relationships among different data entities.
Data modeling simplifies database design and ensures data integrity, quality, and regulatory compliance. The objective is to visually understand and physically structure the data for consistent access and querying.
Building and maintaining data pipelines can be technically challenging and time-consuming. With Hevo, you can easily set up and manage your pipelines without any coding. With its intuitive interface, you can get your pipelines up and running in minutes.
Key-Benefits of using Hevo:
- Real-time data ingestion
- No-code platform
- Pre and Post-load transformations
- Automated Schema Mapping.
Join over 2000+ customers across 45 countries who’ve streamlined their data operations with Hevo. Rated as 4.7 on Capterra, Hevo is the No.1 choice for modern data teams.
Types of Data Modeling
The three primary types of data modeling include:
Conceptual data model
Conceptual data modeling is a high-level view of data without delving into its technical details. Its primary purpose is to identify key entities, their relationships, and relevant concepts for a shared understanding between business and technical users.
A conceptual data model helps your team, and stakeholders understand what kind of data your organization uses and how different entities are related. Think of it as a common language for both business and technical users to understand the essentials and bigger picture of your data.
Logical data model
Logical data model takes the conceptual model entities a step further by providing additional information about them. It offers a detailed overview of storing and organizing the data efficiently without worrying about how it’s physically implemented.
It equips your team with a solid framework for designing and developing databases, warehouses, and data-consuming applications.
Here are some key tasks involved in the logical data model:
- Although some entities and relationships are defined in conceptual data models, you’ll need to identify additional attributes, assign data types, and define detailed relationships to complete the logical model.
- Determine primary keys that uniquely identify records and foreign keys to establish relationships between entities.
- Ensure normalization to reduce data duplicacy and redundancy.
- Defining cardinality like one-to-one, one-to-many, and many-to-many relationships for entities.
- Create entity relationship diagrams to represent entities and their relationships.
Physical data model
A physical data model implements your definitions in conceptual and logical data models to a practical, working database. It contains details about the database schema, including columns, data types, indexes, and primary-foreign key relationships.
Tasks involved in building a physical data model:
- Converting entities into single or multiple tables.
- Attributes in the logical data model are columns in the physical data model.
- Define the relationship between tables using primary and foreign keys.
- Ensure tables adhere to the defined normalization rules.
- Partition tables to optimize performance.
How to do Data Modeling?
Building a complete data model is a crucial phase of creating a successful application. Let’s explore the steps involved in creating a data model, along with an example of a job portal application.
Step 1: Business requirements
The first step is to know the purpose and functions of your application. You should understand the business users requirements for how the application should manage and store data.
For instance, in a job portal, applicants can apply for multiple jobs, and only employers should have access to the candidates’ personal details. These are some of the key functions a business user may require in the application.
Step 2: Create a conceptual data model
This step involves a high-level representation of entities, attributes, and their relationships. We will have to stick to business terminology and technical details, as the physical implementation comes later in other data models. The practical steps involve identifying the key entities and drawing out some general links between them.
In our job portal app example, entities can be:
- Employer: who can post jobs
- Candidate: applies for jobs
- Job posting: jobs posted by employees
- Job application: job applications sent by candidates
Next, describe more about entities, such as what data they store and their data types. For example, a job posting entity contains information about designation, requirements, and salary offered.
Step 3: Define attributes
Convert the entities into tables, where columns represent relevant attributes and rows contain data for each entity instance. Take the job application entity, for example; each row represents a candidate’s details applied for the job, while attributes like job_id, role_name, post_date, location, salary, and employer_id represent columns in that table.
Step 4: Establish relationships
We identified some general links between the entities in previous steps. Now, we need to clearly define the relationships among them. These relationships show how different entities of an application interact with each other.
One-to-one relationship: Take employer_id attribute, for instance, an employer will have only one id, and each id belongs to a single employer. So, they are in a one-to-one relationship.
One-to-many relationship: In this case, one entity is linked to multiple entities. That is, an employer can post several job postings.
Many-to-many relationship: A single candidate can apply to many job_ids, and each job_id can receive multiple candidate applications. Hence, they are in a many-to-many relationship.
Once the relationships between entities are identified, the next task is to determine the primary and foreign keys. Primary column of a table uniquely identifies each row in a table and if this column appears in another table, it becomes a foreign key for that table. These keys are required to build the specified relationship between tables.
Step 5: Create a Logical data model
A logical data model represents the identified entities and established relationships with the help of ERDs or UML diagrams.
Here is a sample ERD representing one-to-many relationship between job posting and employer entities.
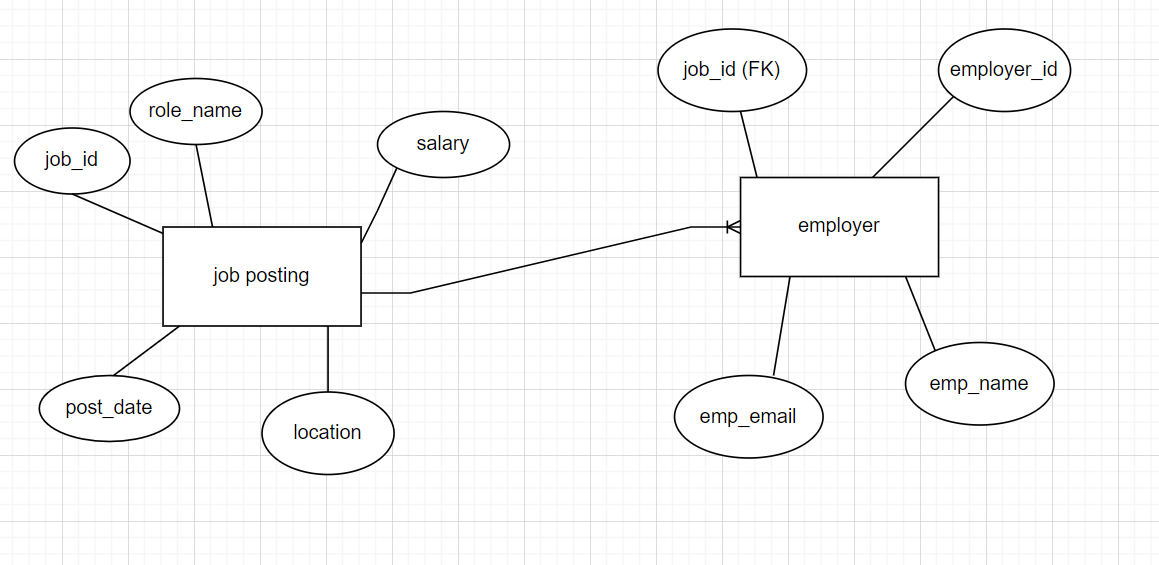
Step 6: Physical data model
Convert the logical structures obtained in the earlier steps into a physical model using a database querying language like SQL. This step also involves connecting the database to various data sources if needed. To connect with external sources, you might need to point to them in your application code.
If you are designing your own database, you’ll need to create internal tables and schema, as shown below.
create table employer (
employer_id int primary key,
emp_name varchar(40),
emp_email varchar(40),
job_id int,
foreign key (job_id) references jobPosting(job_id)
);
create table candidate(
candidate_id int primary key,
candidate_name varchar(40),
candidate_email varchar(40),
candidate_ph_no INT,
candidate_resume TEXT,
);
create table jobPosting (
job_id int primary key,
job_role varchar(40),
location varchar(40),
salary int,
post_date DATE,
recruiter_id int,
foreign key recruiter_id_id references employer(employer_id),
);
create table job_application (
application_id int primary key,
application_date DATE,
job_id int,
jobSeeker_id INT,
foreign key (job_id) references jobPosting(job_id),
foreign key (jobSeeker_id) references candidate(candidate_id)
);Conclusion
In today’s data-rich world, it has become a necessity for developers to understand data modeling to efficiently create software applications that work with data. It also bridges the gap between business users and tech professionals, helping them collaborate to effectively utilize the organizational data.
So, follow the steps mentioned in this article to create a robust data model that organizes your data and enhances its impact on your business and software applications.
Sign up for a 14-day free trial and experience the feature-rich Hevo suite first hand. Check out the Hevo pricing details.
FAQ on Data Modeling
Is data modeling an ETL?
No, data modeling is the design of how data is stored and accessed, while ETL involves collecting data from various sources, transforming it, and loading it to the destination.
What are the four approaches to data modeling?
The four common approaches to data modeling are hierarchical, relational, entity-relationship, and graph.
What are the three basic data modeling techniques?
Conceptual, logical, and physical data models discussed in this blog are the three basic data modeling techniques.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link



